 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault Sneaking Attack: a Stealthy Framework for Misleading Deep Neural Networks
Paper and Code
May 28, 2019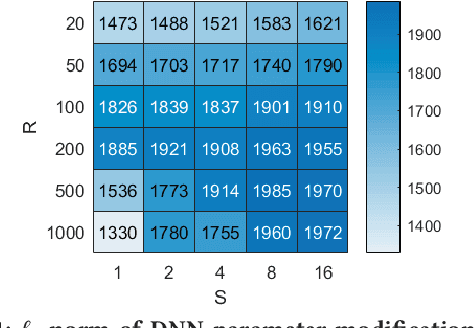
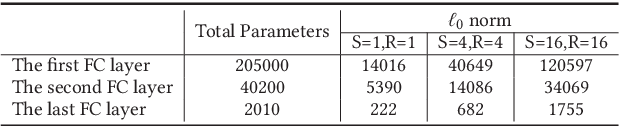
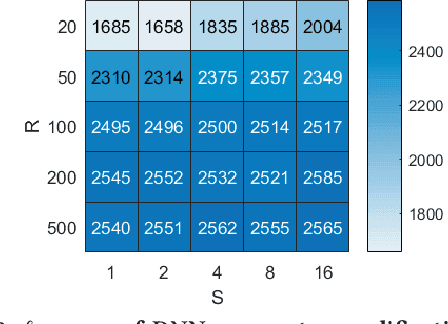

Despite the great achievements of deep neural networks (DNNs), the vulnerability of state-of-the-art DNNs raises security concerns of DNNs in many application domains requiring high reliability.We propose the fault sneaking attack on DNNs, where the adversary aims to misclassify certain input images into any target labels by modifying the DNN parameters. We apply ADMM (alternating direction method of multipliers) for solving the optimization problem of the fault sneaking attack with two constraints: 1) the classification of the other images should be unchanged and 2) the parameter modifications should be minimized. Specifically, the first constraint requires us not only to inject designated faults (misclassifications), but also to hide the faults for stealthy or sneaking considerations by maintaining model accuracy. The second constraint requires us to minimize the parameter modifications (using L0 norm to measure the number of modifications and L2 norm to measure the magnitude of modifications). Comprehensive experimental evaluation demonstrates that the proposed framework can inject multiple sneaking faults without losing the overall test accuracy performance.