 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastMoE: A Fast Mixture-of-Expert Training System
Paper and Code
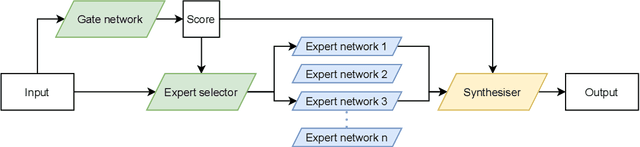
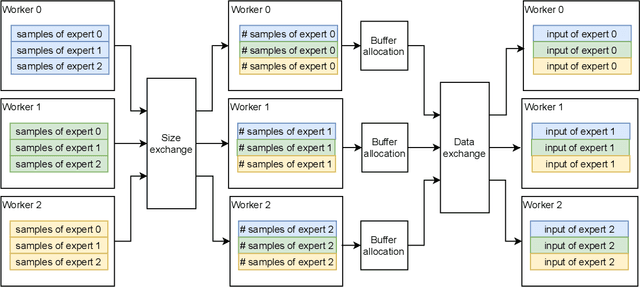
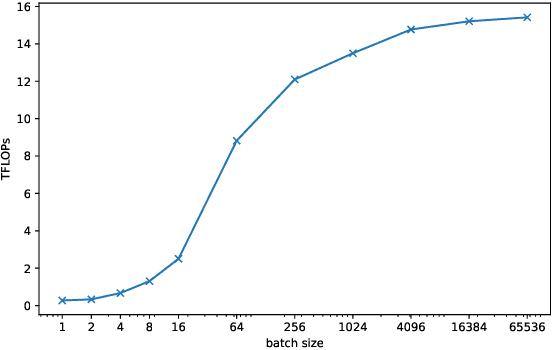

Mixture-of-Expert (MoE) presents a strong potential in enlarging the size of language model to trillions of parameters. However, training trillion-scale MoE requires algorithm and system co-design for a well-tuned high performance distributed training system. Unfortunately, the only existing platform that meets the requirements strongly depends on Google's hardware (TPU) and software (Mesh Tensorflow) stack, and is not open and available to the public, especially GPU and PyTorch communities. In this paper, we present FastMoE, a distributed MoE training system based on PyTorch with common accelerators. The system provides a hierarchical interface for both flexible model design and easy adaption to different applications, such as Transformer-XL and Megatron-LM. Different from direct implementation of MoE models using PyTorch, the training speed is highly optimized in FastMoE by sophisticated high-performance acceleration skills. The system supports placing different experts on multiple GPUs across multiple nodes, enabling enlarging the number of experts linearly against the number of GPUs. The source of FastMoE is available at https://github.com/laekov/fastmoe under Apache-2 license.