 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster PAC Learning and Smaller Coresets via Smoothed Analysis
Paper and Code
Jun 09, 2020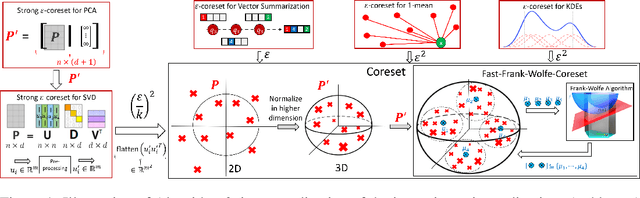
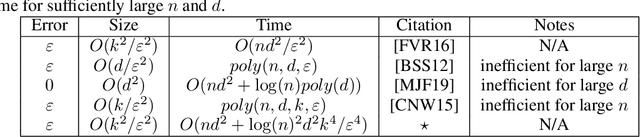
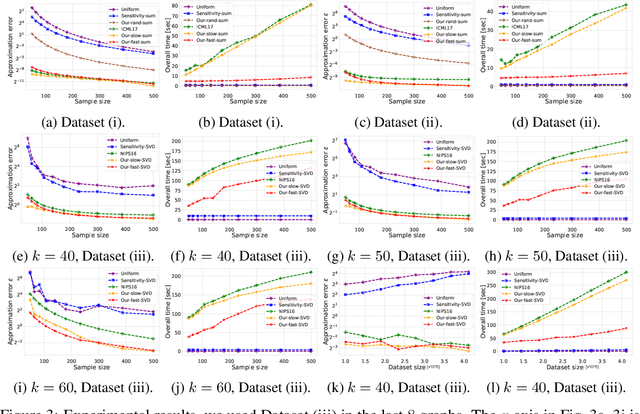
PAC-learning usually aims to compute a small subset ($\varepsilon$-sample/net) from $n$ items, that provably approximates a given loss function for every query (model, classifier, hypothesis) from a given set of queries, up to an additive error $\varepsilon\in(0,1)$. Coresets generalize this idea to support multiplicative error $1\pm\varepsilon$. Inspired by smoothed analysis, we suggest a natural generalization: approximate the \emph{average} (instead of the worst-case) error over the queries, in the hope of getting smaller subsets. The dependency between errors of different queries implies that we may no longer apply the Chernoff-Hoeffding inequality for a fixed query, and then use the VC-dimension or union bound. This paper provides deterministic and randomized algorithms for computing such coresets and $\varepsilon$-samples of size independent of $n$, for any finite set of queries and loss function. Example applications include new and improved coreset constructions for e.g. streaming vector summarization [ICML'17] and $k$-PCA [NIPS'16]. Experimental results with open source code are provided.