 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast video object segmentation with Spatio-Temporal GANs
Paper and Code
Mar 28, 2019
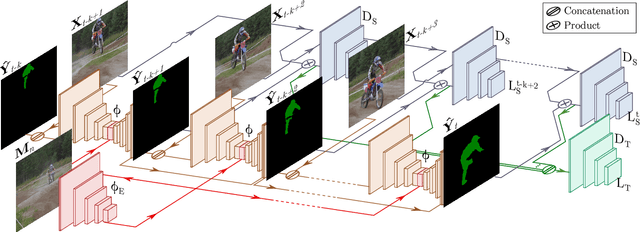

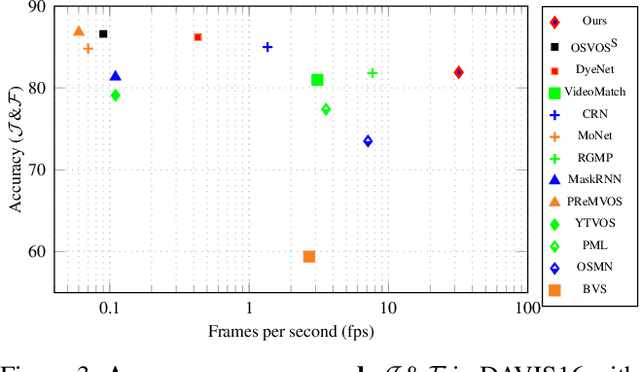
Learning descriptive spatio-temporal object models from data is paramount for the task of semi-supervised video object segmentation. Most existing approaches mainly rely on models that estimate the segmentation mask based on a reference mask at the first frame (aided sometimes by optical flow or the previous mask). These models, however, are prone to fail under rapid appearance changes or occlusions due to their limitations in modelling the temporal component. On the other hand, very recently, other approaches learned long-term features using a convolutional LSTM to leverage the information from all previous video frames. Even though these models achieve better temporal representations, they still have to be fine-tuned for every new video sequence. In this paper, we present an intermediate solution and devise a novel GAN architecture, FaSTGAN, to learn spatio-temporal object models over finite temporal windows. To achieve this, we concentrate all the heavy computational load to the training phase with two critics that enforce spatial and temporal mask consistency over the last K frames. Then at test time, we only use a relatively light regressor, which reduces the inference time considerably. As a result, our approach combines a high resiliency to sudden geometric and photometric object changes with efficiency at test time (no need for fine-tuning nor post-processing). We demonstrate that the accuracy of our method is on par with state-of-the-art techniques on the challenging YouTube-VOS and DAVIS datasets, while running at 32 fps, about 4x faster than the closest competitor.