Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast transcription of speech in low-resource languages
Paper and Code

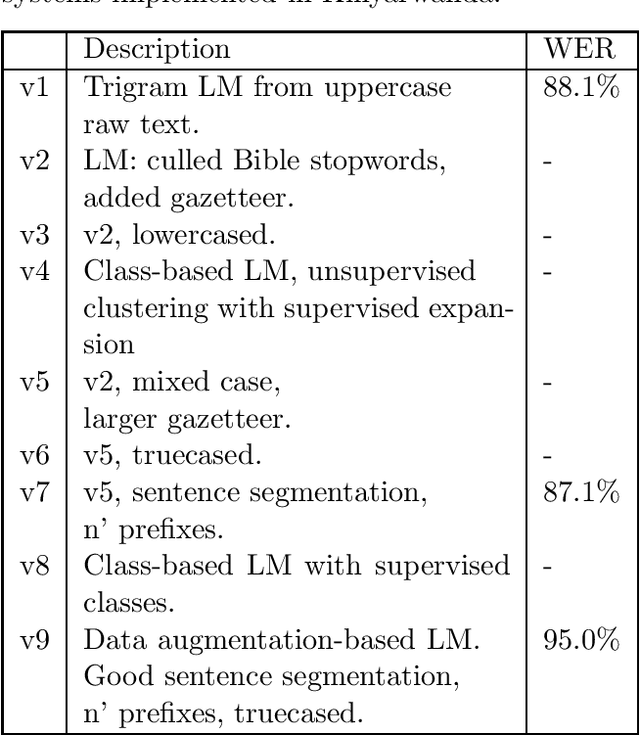

We present software that, in only a few hours, transcribes forty hours of recorded speech in a surprise language, using only a few tens of megabytes of noisy text in that language, and a zero-resource grapheme to phoneme (G2P) table. A pretrained acoustic model maps acoustic features to phonemes; a reversed G2P maps these to graphemes; then a language model maps these to a most-likely grapheme sequence, i.e., a transcription. This software has worked successfully with corpora in Arabic, Assam, Kinyarwanda, Russian, Sinhalese, Swahili, Tagalog, and Tamil.
* 8 pages
View paper on