 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Randomized Kernel Methods With Statistical Guarantees
Paper and Code
Nov 08, 2015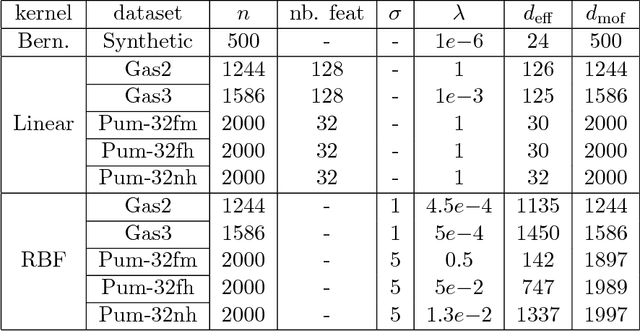
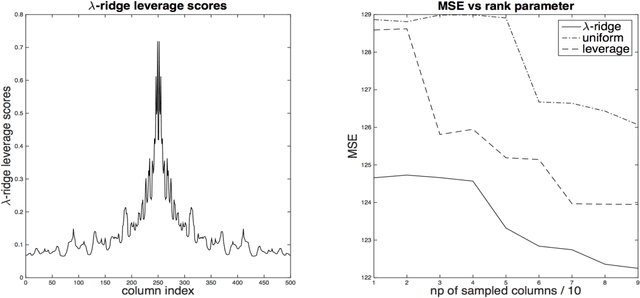
One approach to improving the running time of kernel-based machine learning methods is to build a small sketch of the input and use it in lieu of the full kernel matrix in the machine learning task of interest. Here, we describe a version of this approach that comes with running time guarantees as well as improved guarantees on its statistical performance. By extending the notion of \emph{statistical leverage scores} to the setting of kernel ridge regression, our main statistical result is to identify an importance sampling distribution that reduces the size of the sketch (i.e., the required number of columns to be sampled) to the \emph{effective dimensionality} of the problem. This quantity is often much smaller than previous bounds that depend on the \emph{maximal degrees of freedom}. Our main algorithmic result is to present a fast algorithm to compute approximations to these scores. This algorithm runs in time that is linear in the number of samples---more precisely, the running time is $O(np^2)$, where the parameter $p$ depends only on the trace of the kernel matrix and the regularization parameter---and it can be applied to the matrix of feature vectors, without having to form the full kernel matrix. This is obtained via a variant of length-squared sampling that we adapt to the kernel setting in a way that is of independent interest. Lastly, we provide empirical results illustrating our theory, and we discuss how this new notion of the statistical leverage of a data point captures in a fine way the difficulty of the original statistical learning problem.