 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Mixing of Data Augmentation Algorithms: Bayesian Probit, Logit, and Lasso Regression
Paper and Code
Dec 11, 2024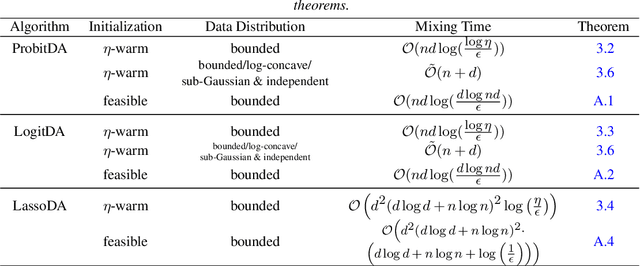
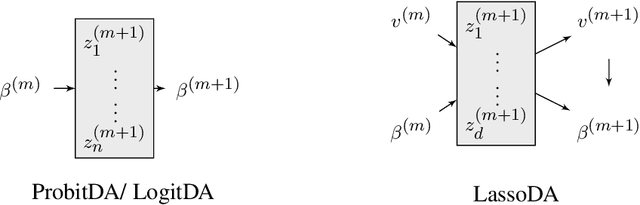
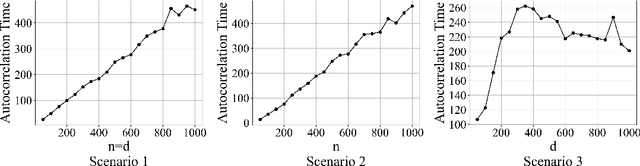
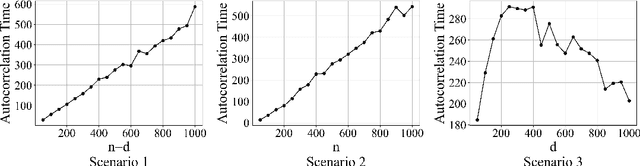
Despite the widespread use of the data augmentation (DA) algorithm, the theoretical understanding of its convergence behavior remains incomplete. We prove the first non-asymptotic polynomial upper bounds on mixing times of three important DA algorithms: DA algorithm for Bayesian Probit regression (Albert and Chib, 1993, ProbitDA), Bayesian Logit regression (Polson, Scott, and Windle, 2013, LogitDA), and Bayesian Lasso regression (Park and Casella, 2008, Rajaratnam et al., 2015, LassoDA). Concretely, we demonstrate that with $\eta$-warm start, parameter dimension $d$, and sample size $n$, the ProbitDA and LogitDA require $\mathcal{O}\left(nd\log \left(\frac{\log \eta}{\epsilon}\right)\right)$ steps to obtain samples with at most $\epsilon$ TV error, whereas the LassoDA requires $\mathcal{O}\left(d^2(d\log d +n \log n)^2 \log \left(\frac{\eta}{\epsilon}\right)\right)$ steps. The results are generally applicable to settings with large $n$ and large $d$, including settings with highly imbalanced response data in the Probit and Logit regression. The proofs are based on the Markov chain conductance and isoperimetric inequalities. Assuming that data are independently generated from either a bounded, sub-Gaussian, or log-concave distribution, we improve the guarantees for ProbitDA and LogitDA to $\tilde{\mathcal{O}}(n+d)$ with high probability, and compare it with the best known guarantees of Langevin Monte Carlo and Metropolis Adjusted Langevin Algorithm. We also discuss the mixing times of the three algorithms under feasible initialization.