 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Learning from Sparse Data
Paper and Code
May 16, 2015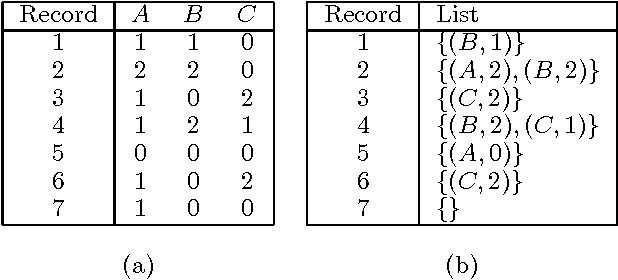
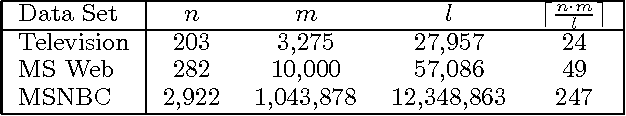
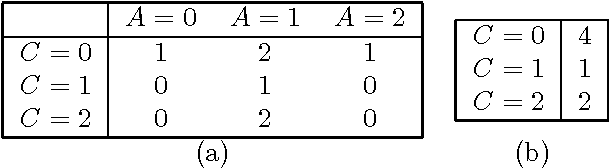
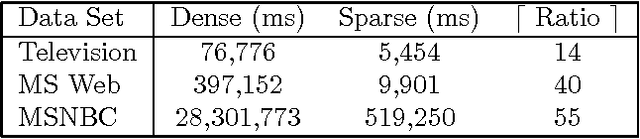
We describe two techniques that significantly improve the running time of several standard machine-learning algorithms when data is sparse. The first technique is an algorithm that effeciently extracts one-way and two-way counts--either real or expected-- from discrete data. Extracting such counts is a fundamental step in learning algorithms for constructing a variety of models including decision trees, decision graphs, Bayesian networks, and naive-Bayes clustering models. The second technique is an algorithm that efficiently performs the E-step of the EM algorithm (i.e. inference) when applied to a naive-Bayes clustering model. Using real-world data sets, we demonstrate a dramatic decrease in running time for algorithms that incorporate these techniques.