 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAST: DNN Training Under Variable Precision Block Floating Point with Stochastic Rounding
Paper and Code
Oct 28, 2021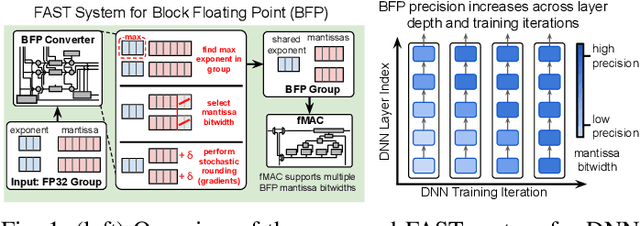
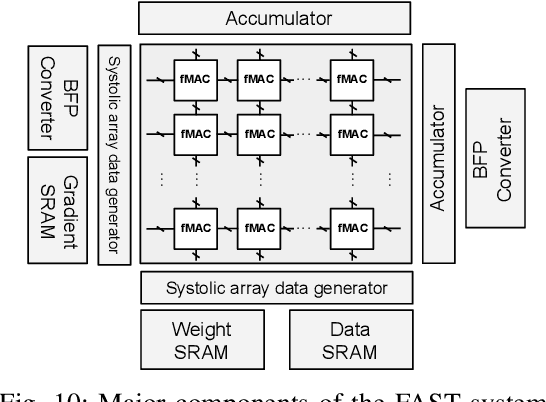
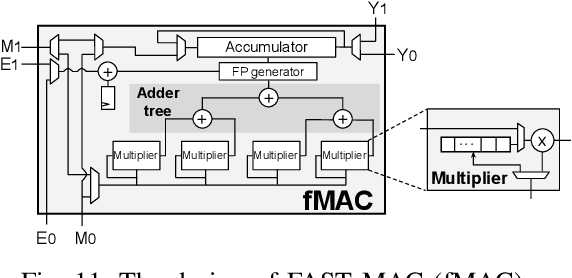
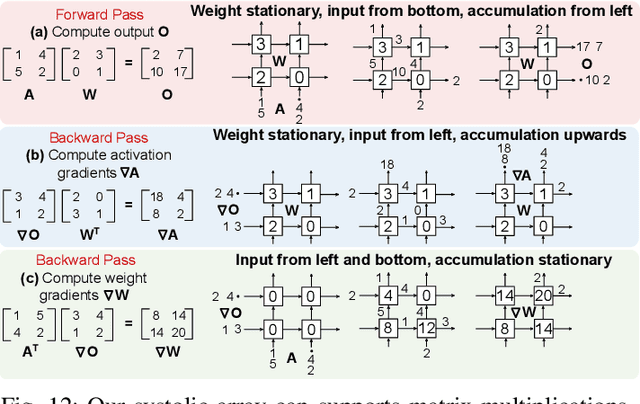
Block Floating Point (BFP) can efficiently support quantization for Deep Neural Network (DNN) training by providing a wide dynamic range via a shared exponent across a group of values. In this paper, we propose a Fast First, Accurate Second Training (FAST) system for DNNs, where the weights, activations, and gradients are represented in BFP. FAST supports matrix multiplication with variable precision BFP input operands, enabling incremental increases in DNN precision throughout training. By increasing the BFP precision across both training iterations and DNN layers, FAST can greatly shorten the training time while reducing overall hardware resource usage. Our FAST Multipler-Accumulator (fMAC) supports dot product computations under multiple BFP precisions. We validate our FAST system on multiple DNNs with different datasets, demonstrating a 2-6$\times$ speedup in training on a single-chip platform over prior work based on \textbf{mixed-precision or block} floating point number systems while achieving similar performance in validation accuracy.