 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Robust Least Squares Estimation in Corrupted Linear Models
Paper and Code
Jun 19, 2014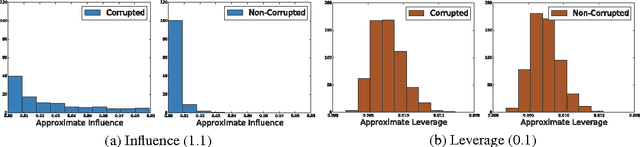
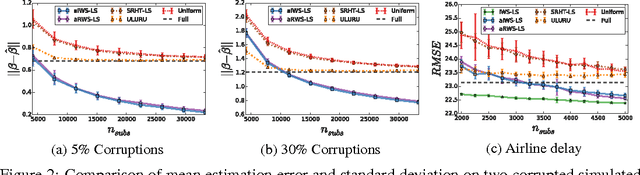
Subsampling methods have been recently proposed to speed up least squares estimation in large scale settings. However, these algorithms are typically not robust to outliers or corruptions in the observed covariates. The concept of influence that was developed for regression diagnostics can be used to detect such corrupted observations as shown in this paper. This property of influence -- for which we also develop a randomized approximation -- motivates our proposed subsampling algorithm for large scale corrupted linear regression which limits the influence of data points since highly influential points contribute most to the residual error. Under a general model of corrupted observations, we show theoretically and empirically on a variety of simulated and real datasets that our algorithm improves over the current state-of-the-art approximation schemes for ordinary least squares.