 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Interpretable Consensus Clustering via Minipatch Learning
Paper and Code
Oct 18, 2021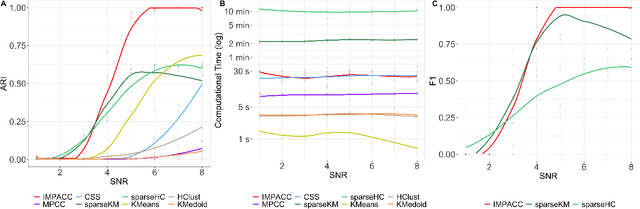
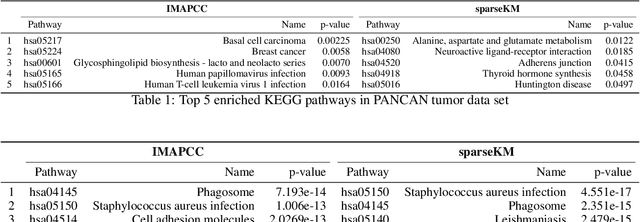
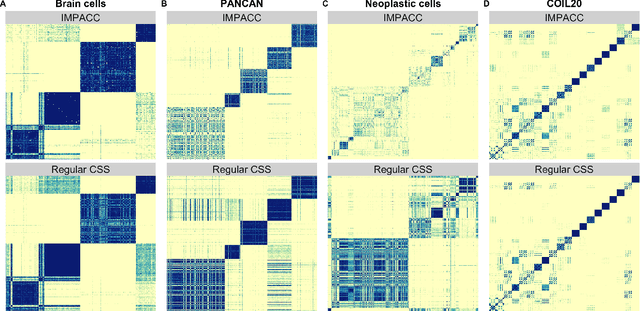
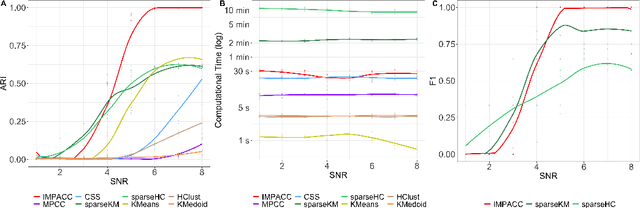
Consensus clustering has been widely used in bioinformatics and other applications to improve the accuracy, stability and reliability of clustering results. This approach ensembles cluster co-occurrences from multiple clustering runs on subsampled observations. For application to large-scale bioinformatics data, such as to discover cell types from single-cell sequencing data, for example, consensus clustering has two significant drawbacks: (i) computational inefficiency due to repeatedly applying clustering algorithms, and (ii) lack of interpretability into the important features for differentiating clusters. In this paper, we address these two challenges by developing IMPACC: Interpretable MiniPatch Adaptive Consensus Clustering. Our approach adopts three major innovations. We ensemble cluster co-occurrences from tiny subsets of both observations and features, termed minipatches, thus dramatically reducing computation time. Additionally, we develop adaptive sampling schemes for observations, which result in both improved reliability and computational savings, as well as adaptive sampling schemes of features, which leads to interpretable solutions by quickly learning the most relevant features that differentiate clusters. We study our approach on synthetic data and a variety of real large-scale bioinformatics data sets; results show that our approach not only yields more accurate and interpretable cluster solutions, but it also substantially improves computational efficiency compared to standard consensus clustering approaches.