 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFar-Field Compression for Fast Kernel Summation Methods in High Dimensions
Paper and Code
Feb 13, 2015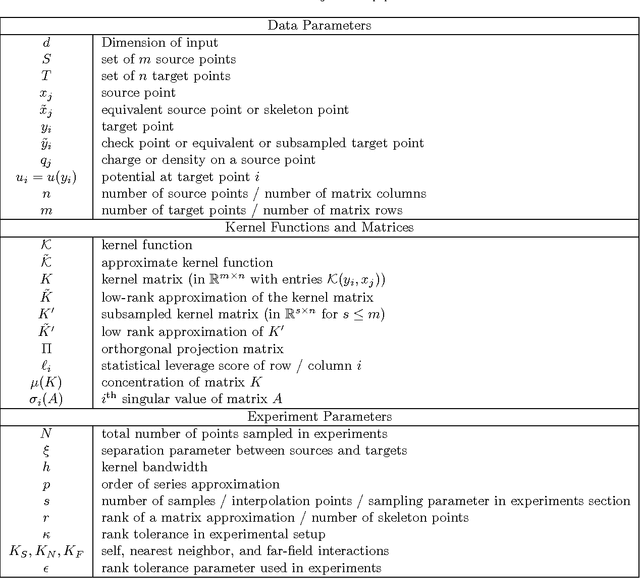
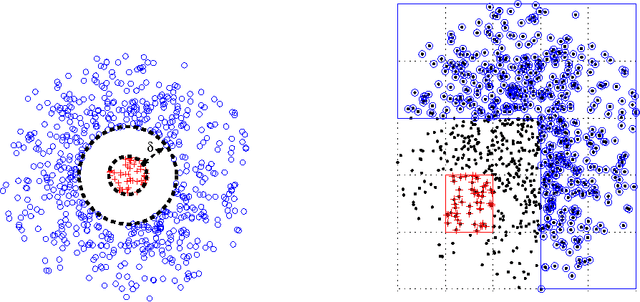
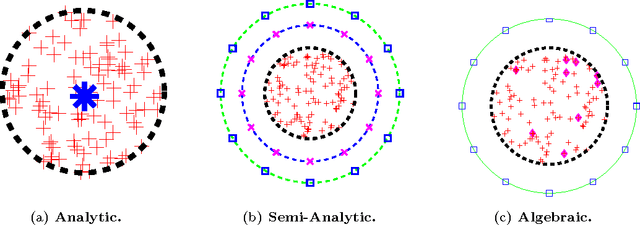
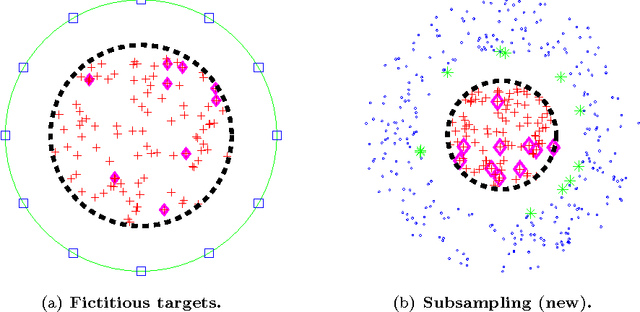
We consider fast kernel summations in high dimensions: given a large set of points in $d$ dimensions (with $d \gg 3$) and a pair-potential function (the {\em kernel} function), we compute a weighted sum of all pairwise kernel interactions for each point in the set. Direct summation is equivalent to a (dense) matrix-vector multiplication and scales quadratically with the number of points. Fast kernel summation algorithms reduce this cost to log-linear or linear complexity. Treecodes and Fast Multipole Methods (FMMs) deliver tremendous speedups by constructing approximate representations of interactions of points that are far from each other. In algebraic terms, these representations correspond to low-rank approximations of blocks of the overall interaction matrix. Existing approaches require an excessive number of kernel evaluations with increasing $d$ and number of points in the dataset. To address this issue, we use a randomized algebraic approach in which we first sample the rows of a block and then construct its approximate, low-rank interpolative decomposition. We examine the feasibility of this approach theoretically and experimentally. We provide a new theoretical result showing a tighter bound on the reconstruction error from uniformly sampling rows than the existing state-of-the-art. We demonstrate that our sampling approach is competitive with existing (but prohibitively expensive) methods from the literature. We also construct kernel matrices for the Laplacian, Gaussian, and polynomial kernels -- all commonly used in physics and data analysis. We explore the numerical properties of blocks of these matrices, and show that they are amenable to our approach. Depending on the data set, our randomized algorithm can successfully compute low rank approximations in high dimensions. We report results for data sets with ambient dimensions from four to 1,000.