 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakeMusicCaps: a Dataset for Detection and Attribution of Synthetic Music Generated via Text-to-Music Models
Paper and Code
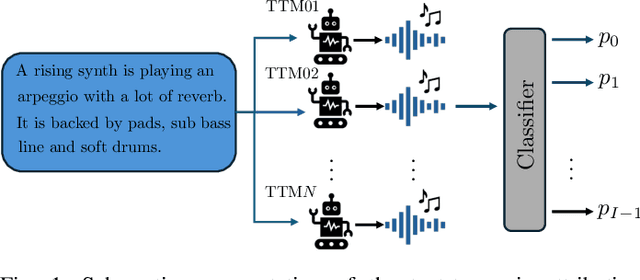
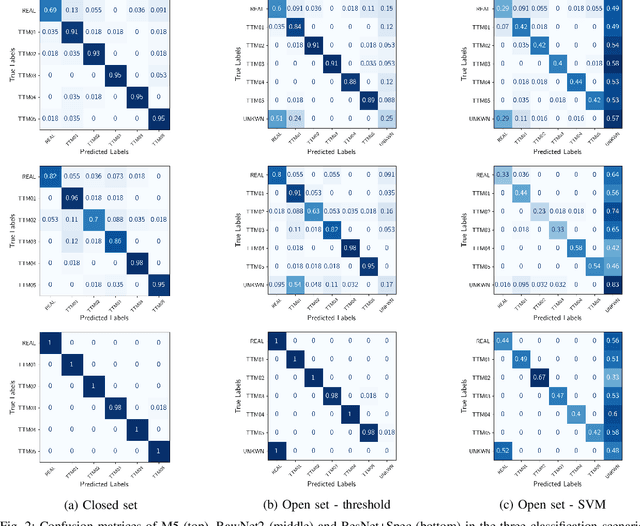


Text-To-Music (TTM) models have recently revolutionized the automatic music generation research field. Specifically, by reaching superior performances to all previous state-of-the-art models and by lowering the technical proficiency needed to use them. Due to these reasons, they have readily started to be adopted for commercial uses and music production practices. This widespread diffusion of TTMs poses several concerns regarding copyright violation and rightful attribution, posing the need of serious consideration of them by the audio forensics community. In this paper, we tackle the problem of detection and attribution of TTM-generated data. We propose a dataset, FakeMusicCaps that contains several versions of the music-caption pairs dataset MusicCaps re-generated via several state-of-the-art TTM techniques. We evaluate the proposed dataset by performing initial experiments regarding the detection and attribution of TTM-generated audio.