 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair mapping
Paper and Code
Sep 01, 2022
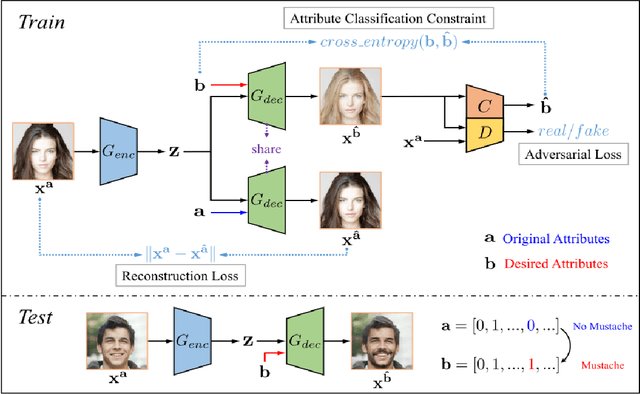
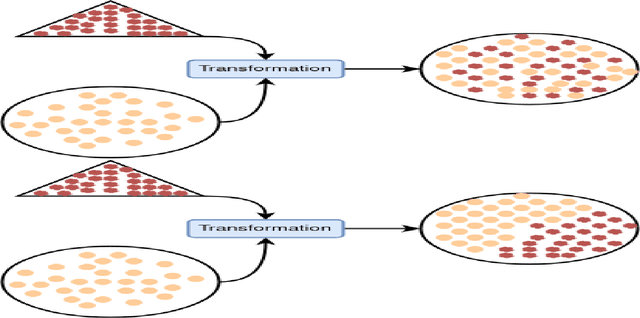

To mitigate the effects of undesired biases in models, several approaches propose to pre-process the input dataset to reduce the risks of discrimination by preventing the inference of sensitive attributes. Unfortunately, most of these pre-processing methods lead to the generation a new distribution that is very different from the original one, thus often leading to unrealistic data. As a side effect, this new data distribution implies that existing models need to be re-trained to be able to make accurate predictions. To address this issue, we propose a novel pre-processing method, that we coin as fair mapping, based on the transformation of the distribution of protected groups onto a chosen target one, with additional privacy constraints whose objective is to prevent the inference of sensitive attributes. More precisely, we leverage on the recent works of the Wasserstein GAN and AttGAN frameworks to achieve the optimal transport of data points coupled with a discriminator enforcing the protection against attribute inference. Our proposed approach, preserves the interpretability of data and can be used without defining exactly the sensitive groups. In addition, our approach can be specialized to model existing state-of-the-art approaches, thus proposing a unifying view on these methods. Finally, several experiments on real and synthetic datasets demonstrate that our approach is able to hide the sensitive attributes, while limiting the distortion of the data and improving the fairness on subsequent data analysis tasks.