 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Decision-making Under Uncertainty
Paper and Code
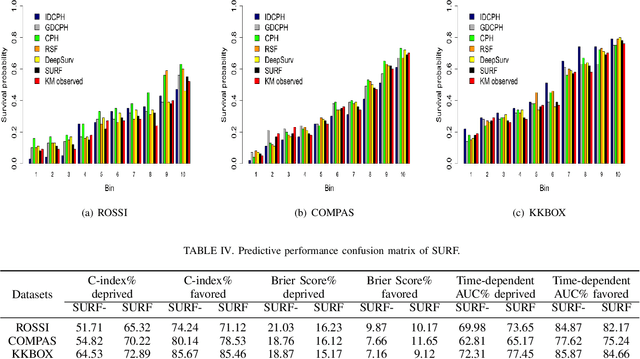
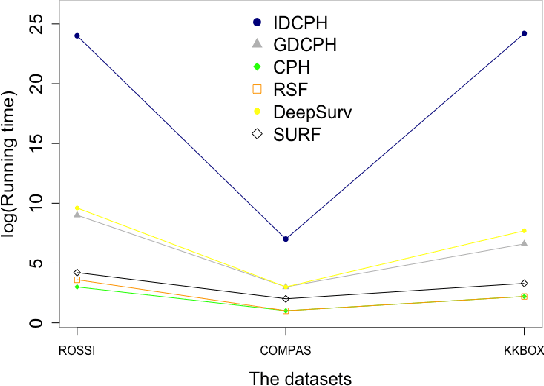


There has been concern within the artificial intelligence (AI) community and the broader society regarding the potential lack of fairness of AI-based decision-making systems. Surprisingly, there is little work quantifying and guaranteeing fairness in the presence of uncertainty which is prevalent in many socially sensitive applications, ranging from marketing analytics to actuarial analysis and recidivism prediction instruments. To this end, we study a longitudinal censored learning problem subject to fairness constraints, where we require that algorithmic decisions made do not affect certain individuals or social groups negatively in the presence of uncertainty on class label due to censorship. We argue that this formulation has a broader applicability to practical scenarios concerning fairness. We show how the newly devised fairness notions involving censored information and the general framework for fair predictions in the presence of censorship allow us to measure and mitigate discrimination under uncertainty that bridges the gap with real-world applications. Empirical evaluations on real-world discriminated datasets with censorship demonstrate the practicality of our approach.