 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Classification with Group-Dependent Label Noise
Paper and Code
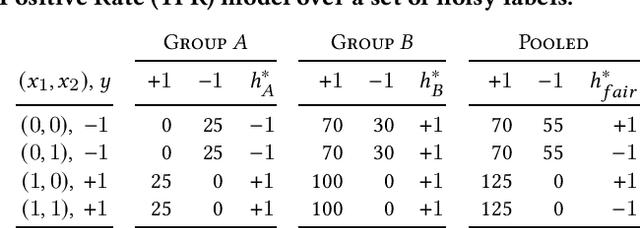
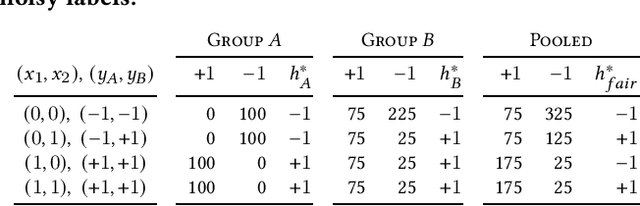


This work examines how to train fair classifiers in settings where training labels are corrupted with random noise, and where the error rates of corruption depend both on the label class and on the membership function for a protected subgroup. Heterogeneous label noise models systematic biases towards particular groups when generating annotations. We begin by presenting analytical results which show that naively imposing parity constraints on demographic disparity measures, without accounting for heterogeneous and group-dependent error rates, can decrease both the accuracy and the fairness of the resulting classifier. Our experiments demonstrate these issues arise in practice as well. We address these problems by performing empirical risk minimization with carefully defined surrogate loss functions and surrogate constraints that help avoid the pitfalls introduced by heterogeneous label noise. We provide both theoretical and empirical justifications for the efficacy of our methods. We view our results as an important example of how imposing fairness on biased data sets without proper care can do at least as much harm as it does good.