 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactoring nonnegative matrices with linear programs
Paper and Code

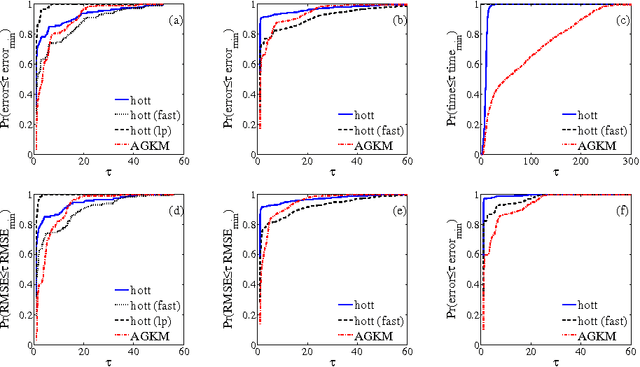
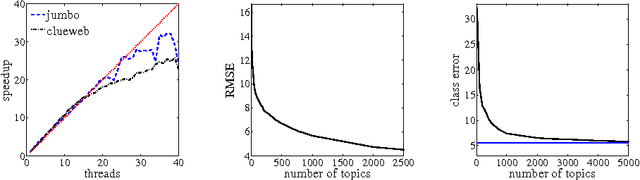
This paper describes a new approach, based on linear programming, for computing nonnegative matrix factorizations (NMFs). The key idea is a data-driven model for the factorization where the most salient features in the data are used to express the remaining features. More precisely, given a data matrix X, the algorithm identifies a matrix C such that X approximately equals CX and some linear constraints. The constraints are chosen to ensure that the matrix C selects features; these features can then be used to find a low-rank NMF of X. A theoretical analysis demonstrates that this approach has guarantees similar to those of the recent NMF algorithm of Arora et al. (2012). In contrast with this earlier work, the proposed method extends to more general noise models and leads to efficient, scalable algorithms. Experiments with synthetic and real datasets provide evidence that the new approach is also superior in practice. An optimized C++ implementation can factor a multigigabyte matrix in a matter of minutes.