 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorbird - a Parameter Server Approach to Distributed Matrix Factorization
Paper and Code
Nov 03, 2014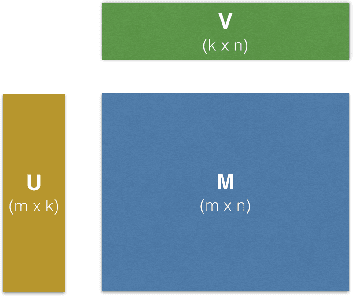
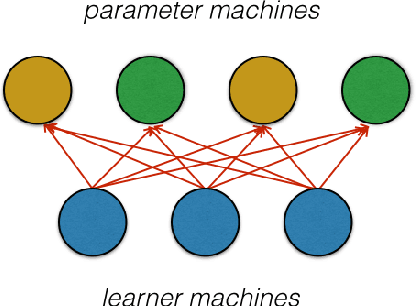
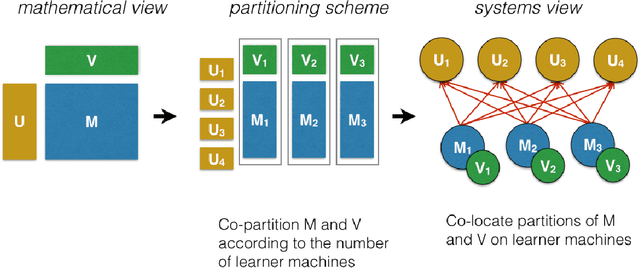
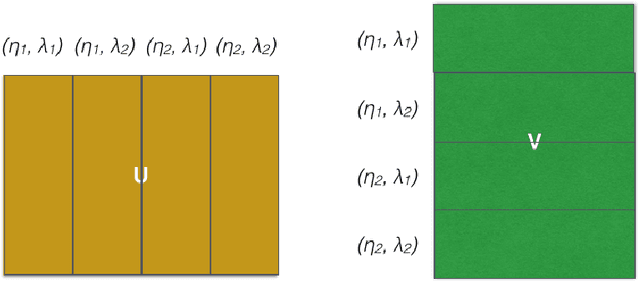
We present Factorbird, a prototype of a parameter server approach for factorizing large matrices with Stochastic Gradient Descent-based algorithms. We designed Factorbird to meet the following desiderata: (a) scalability to tall and wide matrices with dozens of billions of non-zeros, (b) extensibility to different kinds of models and loss functions as long as they can be optimized using Stochastic Gradient Descent (SGD), and (c) adaptability to both batch and streaming scenarios. Factorbird uses a parameter server in order to scale to models that exceed the memory of an individual machine, and employs lock-free Hogwild!-style learning with a special partitioning scheme to drastically reduce conflicting updates. We also discuss other aspects of the design of our system such as how to efficiently grid search for hyperparameters at scale. We present experiments of Factorbird on a matrix built from a subset of Twitter's interaction graph, consisting of more than 38 billion non-zeros and about 200 million rows and columns, which is to the best of our knowledge the largest matrix on which factorization results have been reported in the literature.