 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFact-Saboteurs: A Taxonomy of Evidence Manipulation Attacks against Fact-Verification Systems
Paper and Code

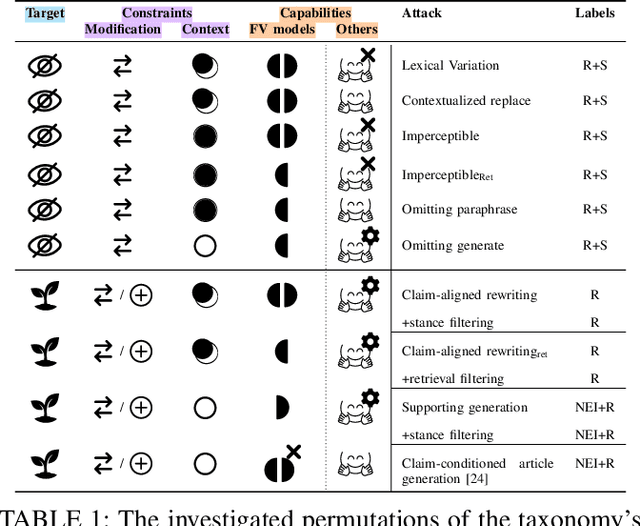
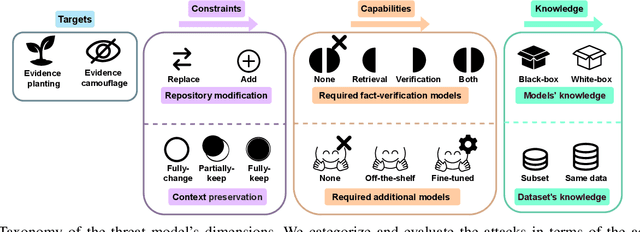
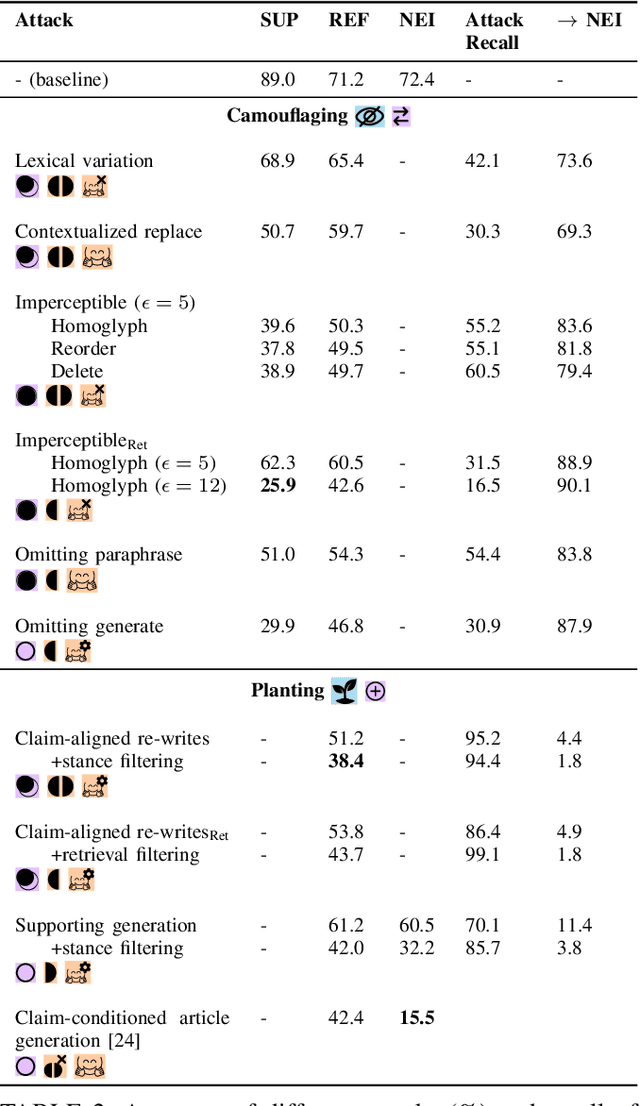
Mis- and disinformation are now a substantial global threat to our security and safety. To cope with the scale of online misinformation, one viable solution is to automate the fact-checking of claims by retrieving and verifying against relevant evidence. While major recent advances have been achieved in pushing forward the automatic fact-verification, a comprehensive evaluation of the possible attack vectors against such systems is still lacking. Particularly, the automated fact-verification process might be vulnerable to the exact disinformation campaigns it is trying to combat. In this work, we assume an adversary that automatically tampers with the online evidence in order to disrupt the fact-checking model via camouflaging the relevant evidence, or planting a misleading one. We first propose an exploratory taxonomy that spans these two targets and the different threat model dimensions. Guided by this, we design and propose several potential attack methods. We show that it is possible to subtly modify claim-salient snippets in the evidence, in addition to generating diverse and claim-aligned evidence. As a result, we highly degrade the fact-checking performance under many different permutations of the taxonomy's dimensions. The attacks are also robust against post-hoc modifications of the claim. Our analysis further hints at potential limitations in models' inference when faced with contradicting evidence. We emphasize that these attacks can have harmful implications on the inspectable and human-in-the-loop usage scenarios of such models, and we conclude by discussing challenges and directions for future defenses.