 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Landmark Predictions with Applications to Metaverse
Paper and Code
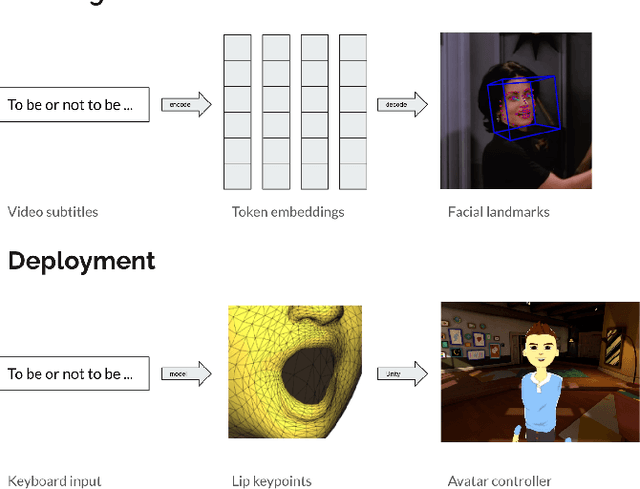
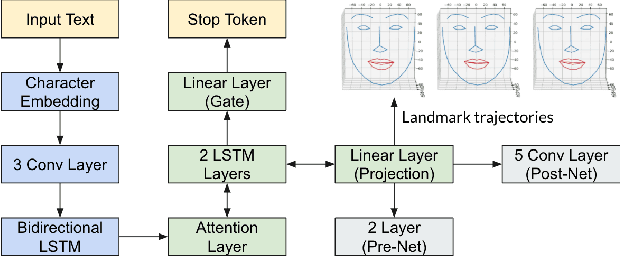


This research aims to make metaverse characters more realistic by adding lip animations learnt from videos in the wild. To achieve this, our approach is to extend Tacotron 2 text-to-speech synthesizer to generate lip movements together with mel spectrogram in one pass. The encoder and gate layer weights are pre-trained on LJ Speech 1.1 data set while the decoder is retrained on 93 clips of TED talk videos extracted from LRS 3 data set. Our novel decoder predicts displacement in 20 lip landmark positions across time, using labels automatically extracted by OpenFace 2.0 landmark predictor. Training converged in 7 hours using less than 5 minutes of video. We conducted ablation study for Pre/Post-Net and pre-trained encoder weights to demonstrate the effectiveness of transfer learning between audio and visual speech data.