 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye-for-an-eye: Appearance Transfer with Semantic Correspondence in Diffusion Models
Paper and Code


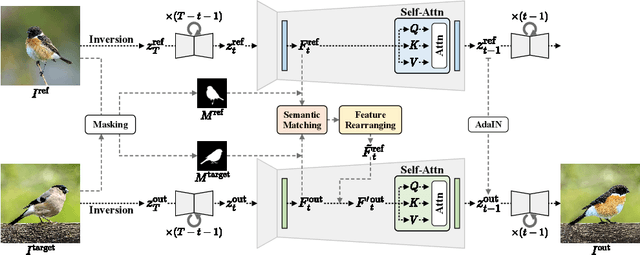

As pretrained text-to-image diffusion models have become a useful tool for image synthesis, people want to specify the results in various ways. In this paper, we introduce a method to produce results with the same structure of a target image but painted with colors from a reference image, i.e., appearance transfer, especially following the semantic correspondence between the result and the reference. E.g., the result wing takes color from the reference wing, not the reference head. Existing methods rely on the query-key similarity within self-attention layer, usually producing defective results. To this end, we propose to find semantic correspondences and explicitly rearrange the features according to the semantic correspondences. Extensive experiments show the superiority of our method in various aspects: preserving the structure of the target and reflecting the color from the reference according to the semantic correspondences, even when the two images are not aligned.