 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive power of outer product manifolds on feed-forward neural networks
Paper and Code
Jul 17, 2018
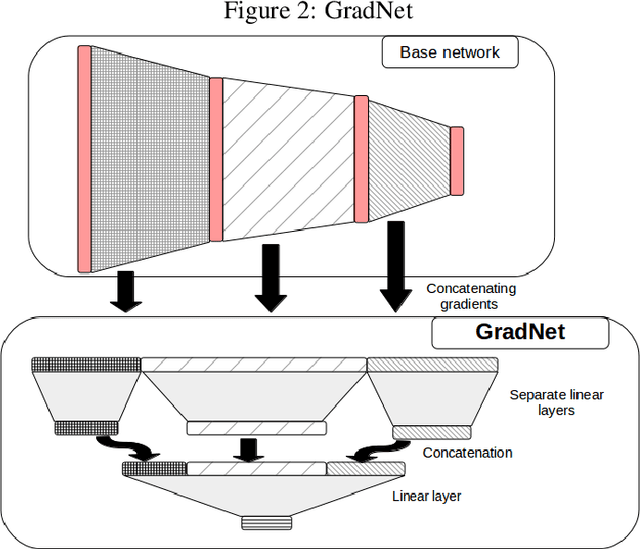
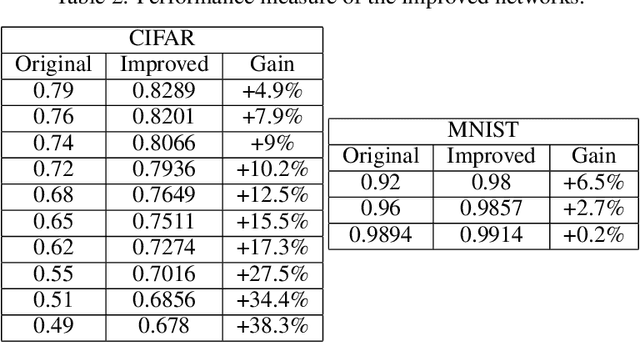
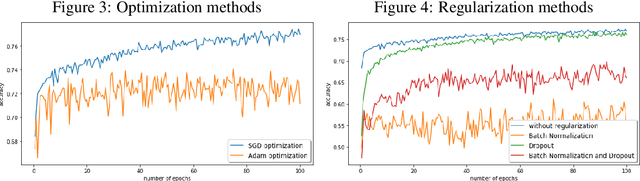
Hierarchical neural networks are exponentially more efficient than their corresponding "shallow" counterpart with the same expressive power, but involve huge number of parameters and require tedious amounts of training. Our main idea is to mathematically understand and describe the hierarchical structure of feedforward neural networks by reparametrization invariant Riemannian metrics. By computing or approximating the tangent subspace, we better utilize the original network via sparse representations that enables switching to shallow networks after a very early training stage. Our experiments show that the proposed approximation of the metric improves and sometimes even surpasses the achievable performance of the original network significantly even after a few epochs of training the original feedforward network.