 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Transformers for Large-Scale Speech Recognition
Paper and Code
May 19, 2020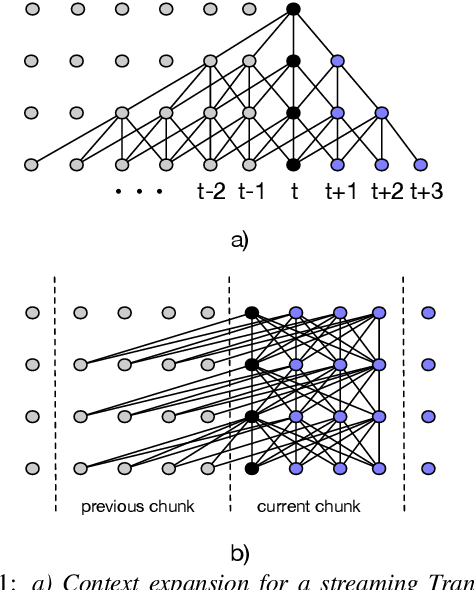
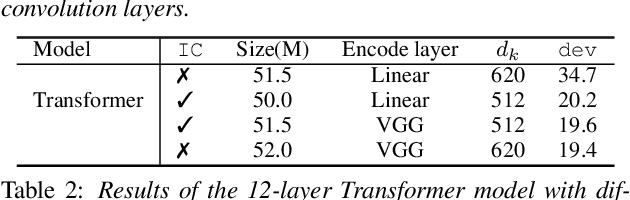

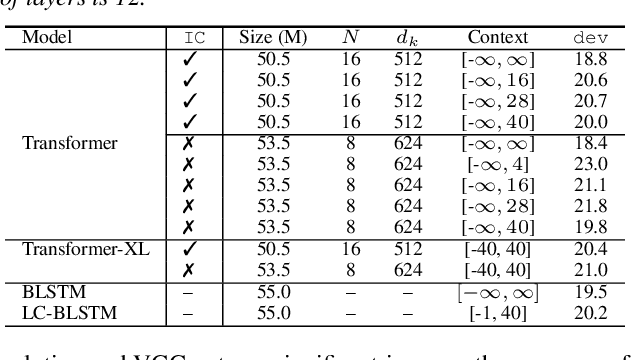
While recurrent neural networks still largely define state-of-the-art speech recognition systems, the Transformer network has been proven to be a competitive alternative, especially in the offline condition. Most studies with Transformers have been constrained in a relatively small scale setting, and some forms of data argumentation approaches are usually applied to combat the data sparsity issue. In this paper, we aim at understanding the behaviors of Transformers in the large-scale speech recognition setting, where we have used around 65,000 hours of training data. We investigated various aspects on scaling up Transformers, including model initialization, warmup training as well as different Layer Normalization strategies. In the streaming condition, we compared the widely used attention mask based future context lookahead approach to the Transformer-XL network. From our experiments, we show that Transformers can achieve around 6% relative word error rate (WER) reduction compared to the BLSTM baseline in the offline fashion, while in the streaming fashion, Transformer-XL is comparable to LC-BLSTM with 800 millisecond latency constraint.