 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration-Enhanced POLITEX
Paper and Code
Aug 27, 2019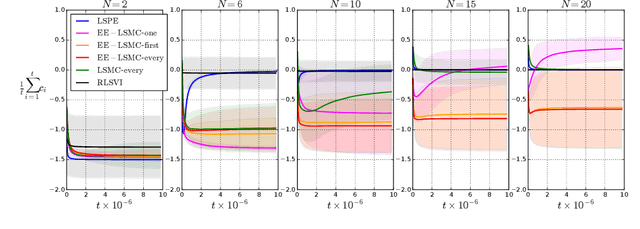
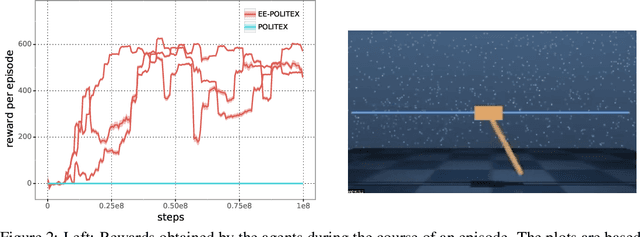
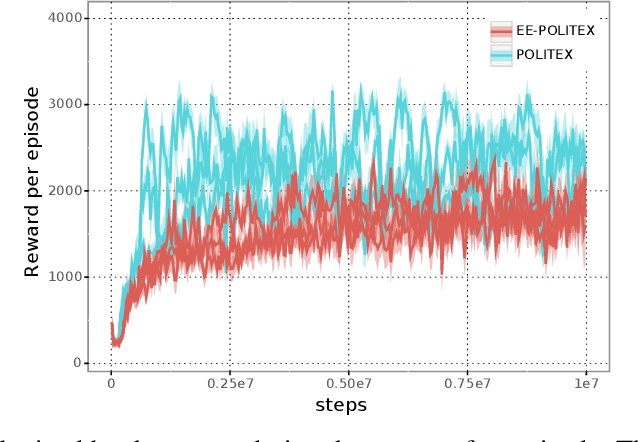
We study algorithms for average-cost reinforcement learning problems with value function approximation. Our starting point is the recently proposed POLITEX algorithm, a version of policy iteration where the policy produced in each iteration is near-optimal in hindsight for the sum of all past value function estimates. POLITEX has sublinear regret guarantees in uniformly-mixing MDPs when the value estimation error can be controlled, which can be satisfied if all policies sufficiently explore the environment. Unfortunately, this assumption is often unrealistic. Motivated by the rapid growth of interest in developing policies that learn to explore their environment in the lack of rewards (also known as no-reward learning), we replace the previous assumption that all policies explore the environment with that a single, sufficiently exploring policy is available beforehand. The main contribution of the paper is the modification of POLITEX to incorporate such an exploration policy in a way that allows us to obtain a regret guarantee similar to the previous one but without requiring that all policies explore environment. In addition to the novel theoretical guarantees, we demonstrate the benefits of our scheme on environments which are difficult to explore using simple schemes like dithering. While the solution we obtain may not achieve the best possible regret, it is the first result that shows how to control the regret in the presence of function approximation errors on problems where exploration is nontrivial. Our approach can also be seen as a way of reducing the problem of minimizing the regret to learning a good exploration policy. We believe that modular approaches like ours can be highly beneficial in tackling harder control problems.