 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Single-Channel Speech For Multi-channel End-to-end Speech Recognition
Paper and Code
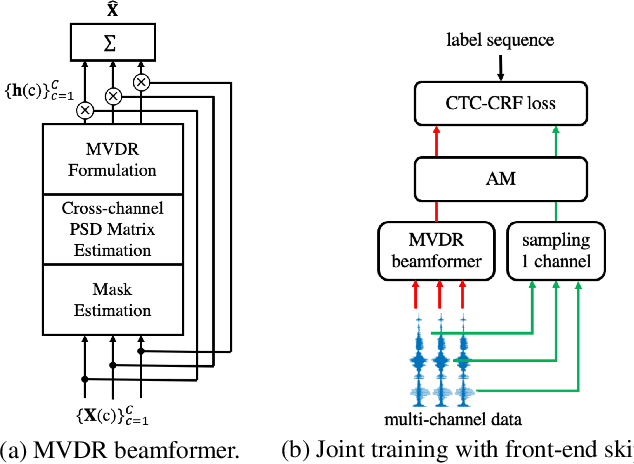

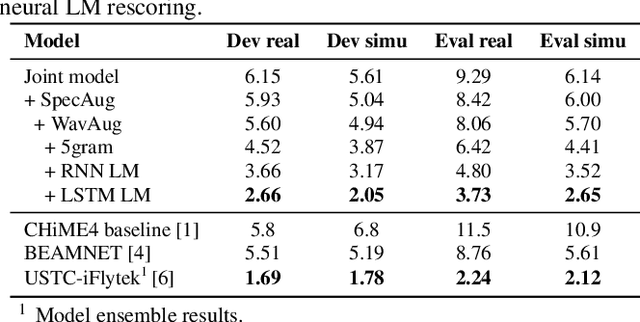
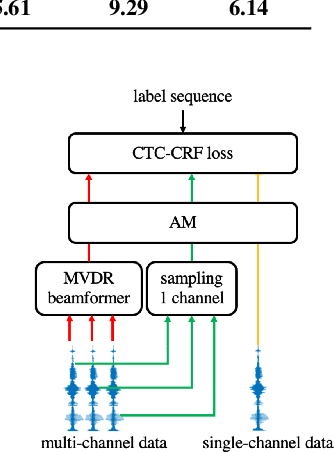
Recently, the end-to-end training approach for neural beamformer-supported multi-channel ASR has shown its effectiveness in multi-channel speech recognition. However, the integration of multiple modules makes it more difficult to perform end-to-end training, particularly given that the multi-channel speech corpus recorded in real environments with a sizeable data scale is relatively limited. This paper explores the usage of single-channel data to improve the multi-channel end-to-end speech recognition system. Specifically, we design three schemes to exploit the single-channel data, namely pre-training, data scheduling, and data simulation. Extensive experiments on CHiME4 and AISHELL-4 datasets demonstrate that all three methods improve the multi-channel end-to-end training stability and speech recognition performance, while the data scheduling approach keeps a much simpler pipeline (vs. pre-training) and less computation cost (vs. data simulation). Moreover, we give a thorough analysis of our systems, including how the performance is affected by the choice of front-end, the data augmentation, training strategy, and single-channel data size.