Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Correlation in Finite-Armed Structured Bandits
Paper and Code
Oct 18, 2018
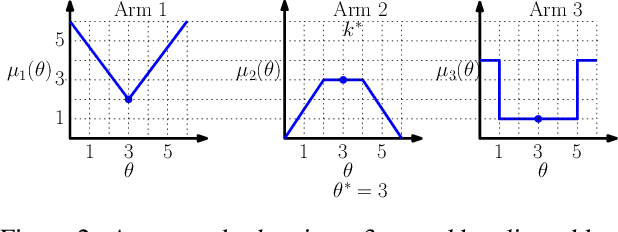
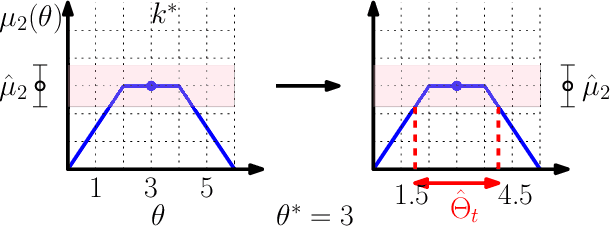
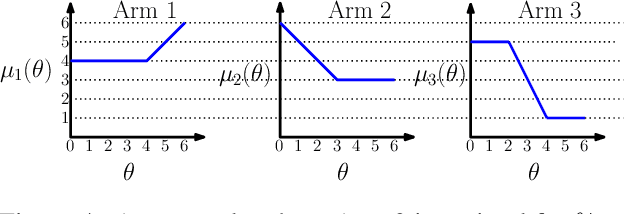
We consider a correlated multi-armed bandit problem in which rewards of arms are correlated through a hidden parameter. Our approach exploits the correlation among arms to identify some arms as sub-optimal and pulls them only $\mathcal{O}(1)$ times. This results in significant reduction in cumulative regret, and in fact our algorithm achieves bounded (i.e., $\mathcal{O}(1)$) regret whenever possible; explicit conditions needed for bounded regret to be possible are also provided by analyzing regret lower bounds. We propose several variants of our approach that generalize classical bandit algorithms such as UCB, Thompson sampling, KL-UCB to the structured bandit setting, and empirically demonstrate their superiority via simulations.
View paper on