 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Estimation of Magnitude and Phase Spectra in Parallel for High-Quality Speech Enhancement
Paper and Code
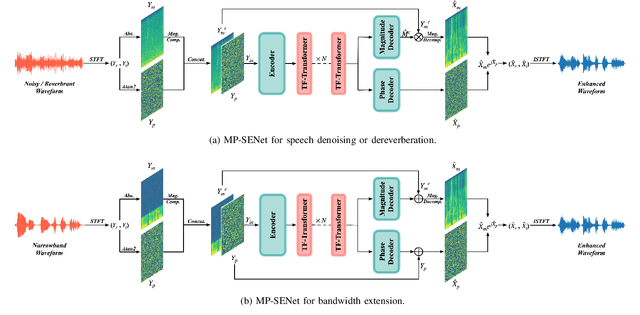
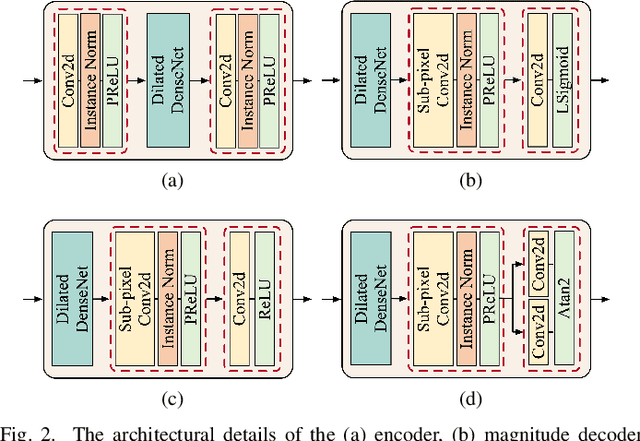
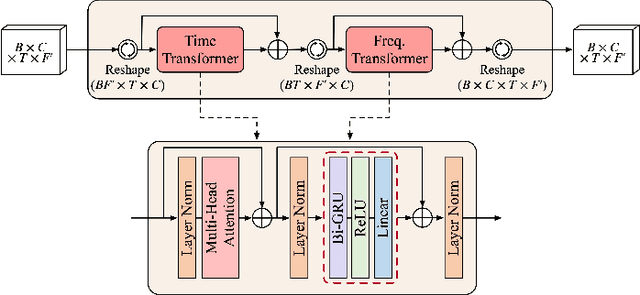
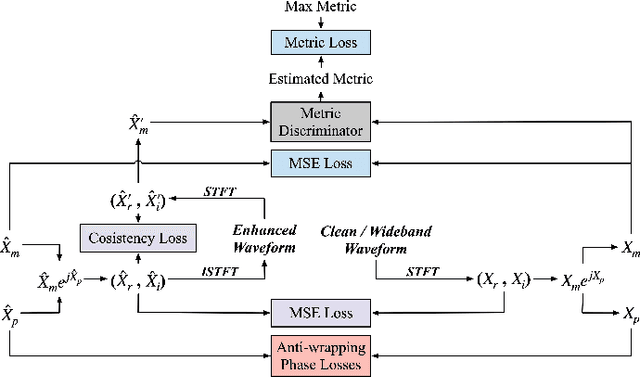
Phase information has a significant impact on speech perceptual quality and intelligibility. However, existing speech enhancement methods encounter limitations in explicit phase estimation due to the non-structural nature and wrapping characteristics of the phase, leading to a bottleneck in enhanced speech quality. To overcome the above issue, in this paper, we proposed MP-SENet, a novel Speech Enhancement Network which explicitly enhances Magnitude and Phase spectra in parallel. The proposed MP-SENet adopts a codec architecture in which the encoder and decoder are bridged by time-frequency Transformers along both time and frequency dimensions. The encoder aims to encode time-frequency representations derived from the input distorted magnitude and phase spectra. The decoder comprises dual-stream magnitude and phase decoders, directly enhancing magnitude and wrapped phase spectra by incorporating a magnitude estimation architecture and a phase parallel estimation architecture, respectively. To train the MP-SENet model effectively, we define multi-level loss functions, including mean square error and perceptual metric loss of magnitude spectra, anti-wrapping loss of phase spectra, as well as mean square error and consistency loss of short-time complex spectra. Experimental results demonstrate that our proposed MP-SENet excels in high-quality speech enhancement across multiple tasks, including speech denoising, dereverberation, and bandwidth extension. Compared to existing phase-aware speech enhancement methods, it successfully avoids the bidirectional compensation effect between the magnitude and phase, leading to a better harmonic restoration. Notably, for the speech denoising task, the MP-SENet yields a state-of-the-art performance with a PESQ of 3.60 on the public VoiceBank+DEMAND dataset.