 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Computation of Input Weights in Extreme Learning Machines
Paper and Code
Jun 11, 2014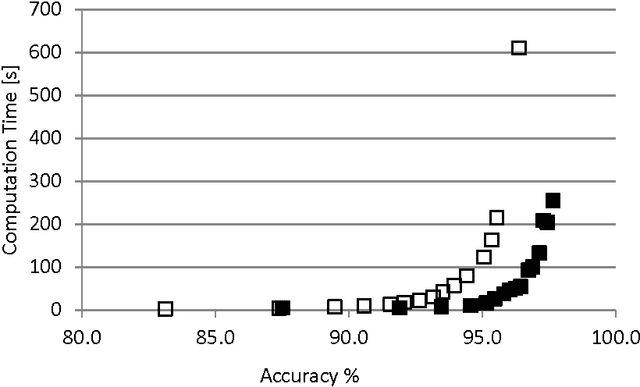
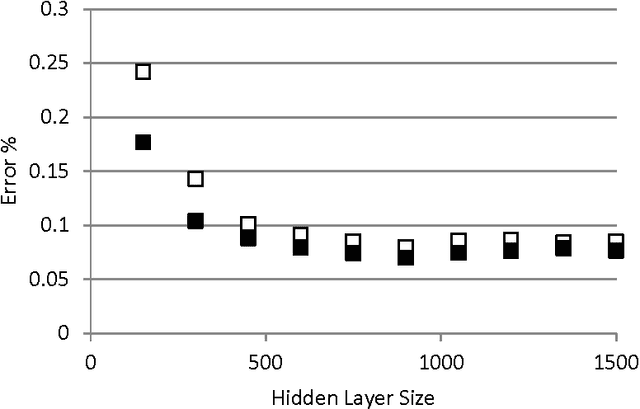
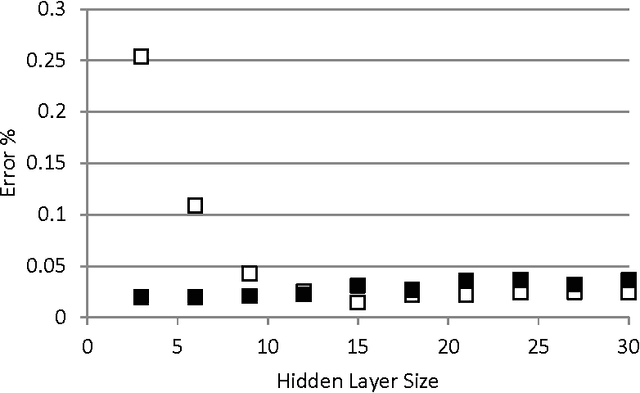
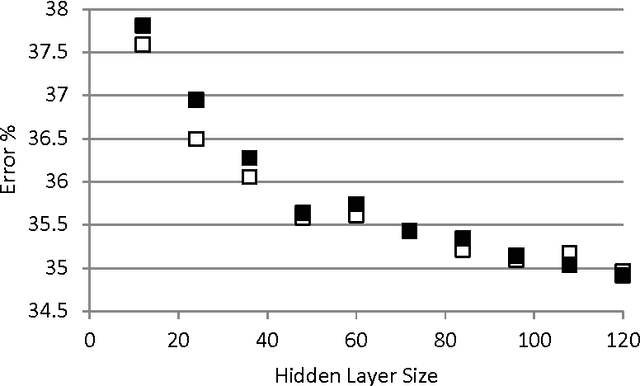
We present a closed form expression for initializing the input weights in a multi-layer perceptron, which can be used as the first step in synthesis of an Extreme Learning Ma-chine. The expression is based on the standard function for a separating hyperplane as computed in multilayer perceptrons and linear Support Vector Machines; that is, as a linear combination of input data samples. In the absence of supervised training for the input weights, random linear combinations of training data samples are used to project the input data to a higher dimensional hidden layer. The hidden layer weights are solved in the standard ELM fashion by computing the pseudoinverse of the hidden layer outputs and multiplying by the desired output values. All weights for this method can be computed in a single pass, and the resulting networks are more accurate and more consistent on some standard problems than regular ELM networks of the same size.