 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Verbal Deception Detection using Transformers
Paper and Code
Oct 06, 2022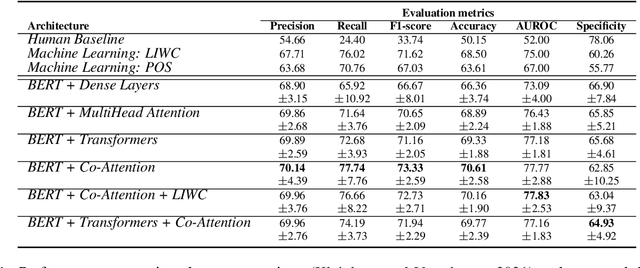
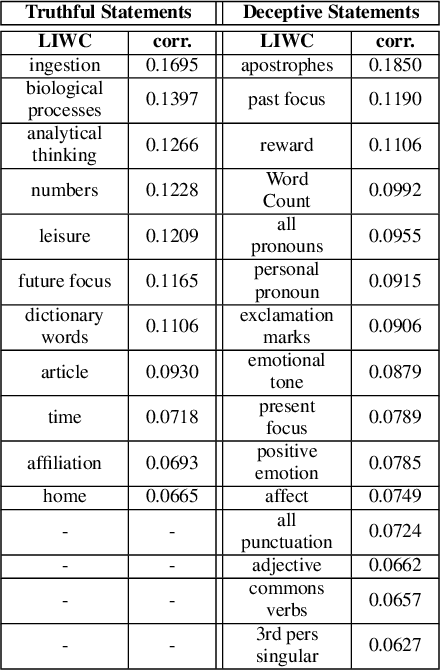
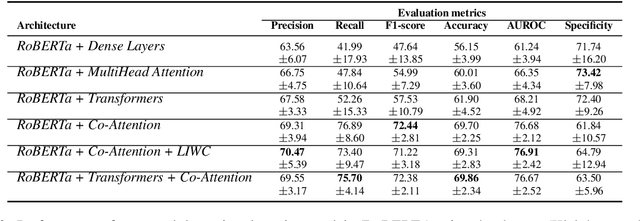
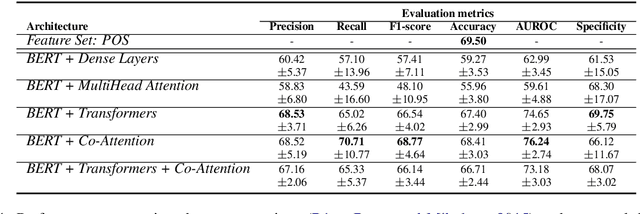
People are regularly confronted with potentially deceptive statements (e.g., fake news, misleading product reviews, or lies about activities). Only few works on automated text-based deception detection have exploited the potential of deep learning approaches. A critique of deep-learning methods is their lack of interpretability, preventing us from understanding the underlying (linguistic) mechanisms involved in deception. However, recent advancements have made it possible to explain some aspects of such models. This paper proposes and evaluates six deep-learning models, including combinations of BERT (and RoBERTa), MultiHead Attention, co-attentions, and transformers. To understand how the models reach their decisions, we then examine the model's predictions with LIME. We then zoom in on vocabulary uniqueness and the correlation of LIWC categories with the outcome class (truthful vs deceptive). The findings suggest that our transformer-based models can enhance automated deception detection performances (+2.11% in accuracy) and show significant differences pertinent to the usage of LIWC features in truthful and deceptive statements.