 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert-Level Atari Imitation Learning from Demonstrations Only
Paper and Code
Sep 09, 2019

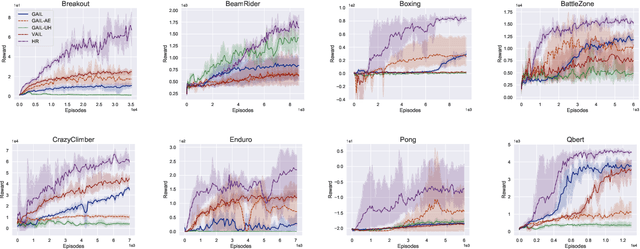
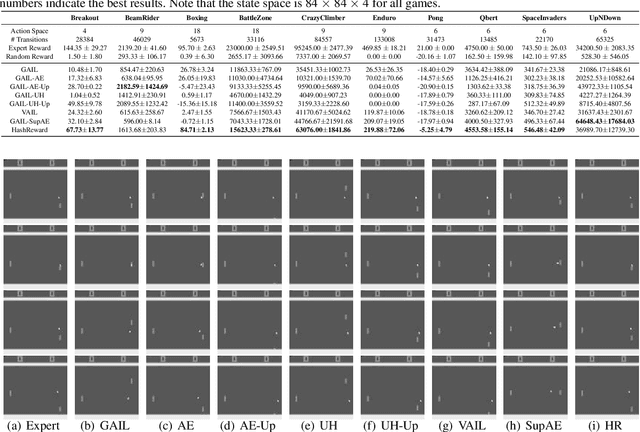
One of the key issues for imitation learning lies in making policy learned from limited samples to generalize well in the whole state-action space. This problem is much more severe in high-dimensional state environments, such as game playing with raw pixel inputs. Under this situation, even state-of-the-art adversary based imitation learning algorithms fail. Through theoretical and empirical studies, we find that the main cause lies in the failure of training a powerful discriminator to generate meaningful rewards in high-dimensional environments. Theoretical results are provided to suggest the necessity of dimensionality reduction. However, since preserving important discriminative information via feature transformation is a non-trivial task, a straightforward application of off-the-shelf methods cannot achieve desirable performance. To address the above issues, we propose HashReward, which is a novel imitation learning algorithm utilizing the idea of supervised hashing to realize effective training of the discriminator. As far as we are aware, HashReward is the first pure imitation learning approach to achieve expert comparable performance in Atari game environments with raw pixel inputs.