 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental Evaluation of Deep Learning models for Marathi Text Classification
Paper and Code
Jan 14, 2021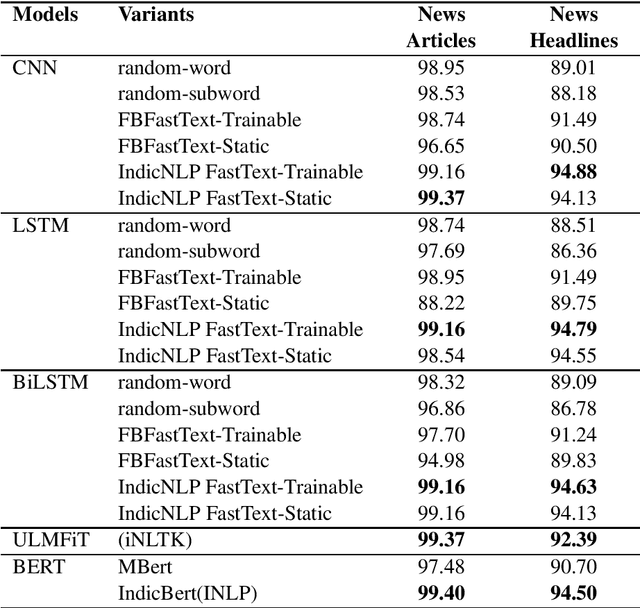
The Marathi language is one of the prominent languages used in India. It is predominantly spoken by the people of Maharashtra. Over the past decade, the usage of language on online platforms has tremendously increased. However, research on Natural Language Processing (NLP) approaches for Marathi text has not received much attention. Marathi is a morphologically rich language and uses a variant of the Devanagari script in the written form. This works aims to provide a comprehensive overview of available resources and models for Marathi text classification. We evaluate CNN, LSTM, ULMFiT, and BERT based models on two publicly available Marathi text classification datasets and present a comparative analysis. The pre-trained Marathi fast text word embeddings by Facebook and IndicNLP are used in conjunction with word-based models. We show that basic single layer models based on CNN and LSTM coupled with FastText embeddings perform on par with the BERT based models on the available datasets. We hope our paper aids focused research and experiments in the area of Marathi NLP.