 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpectation propagation for the diluted Bayesian classifier
Paper and Code
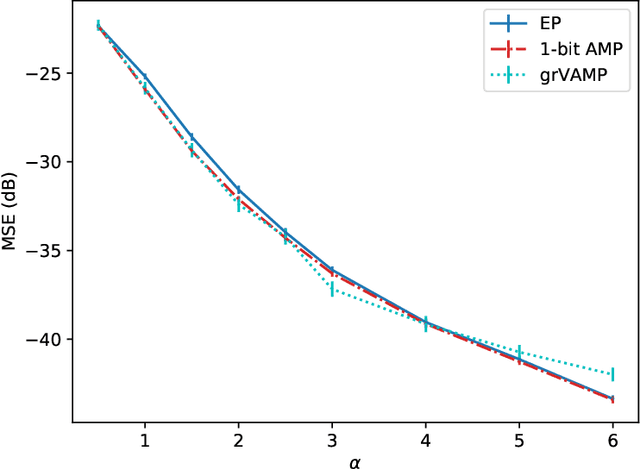
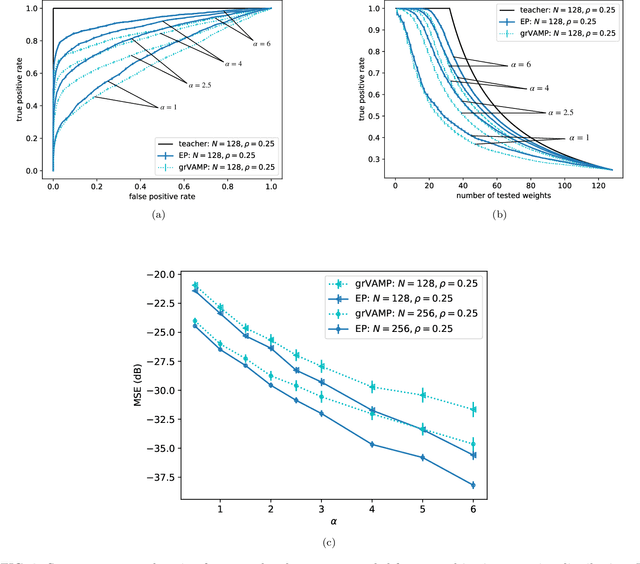
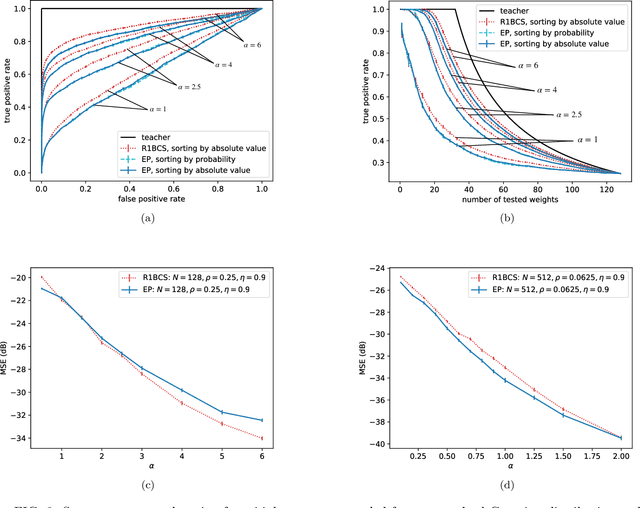
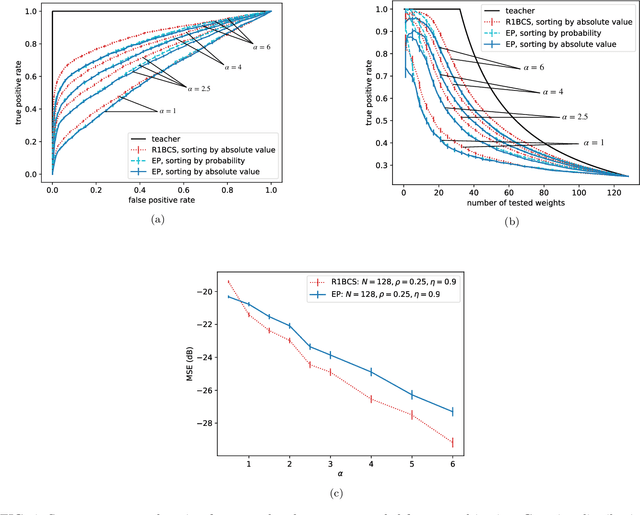
Efficient feature selection from high-dimensional datasets is a very important challenge in many data-driven fields of science and engineering. We introduce a statistical mechanics inspired strategy that addresses the problem of sparse feature selection in the context of binary classification by leveraging a computational scheme known as expectation propagation (EP). The algorithm is used in order to train a continuous-weights perceptron learning a classification rule from a set of (possibly partly mislabeled) examples provided by a teacher perceptron with diluted continuous weights. We test the method in the Bayes optimal setting under a variety of conditions and compare it to other state-of-the-art algorithms based on message passing and on expectation maximization approximate inference schemes. Overall, our simulations show that EP is a robust and competitive algorithm in terms of variable selection properties, estimation accuracy and computationally complexity, especially when the student perceptron is trained from correlated patterns that prevent other iterative methods from converging. Furthermore, our numerical tests demonstrate that the algorithm is capable of learning online the unknown values of prior parameters, such as the dilution level of the weights of the teacher perceptron and the fraction of mislabeled examples, quite accurately. This is achieved by means of a simple maximum likelihood strategy that consists in minimizing the free energy associated with the EP algorithm.