 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpansive Synthesis: Generating Large-Scale Datasets from Minimal Samples
Paper and Code
Jun 25, 2024
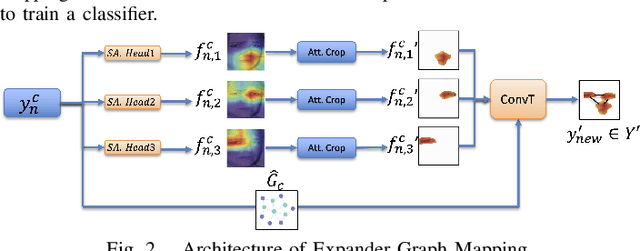
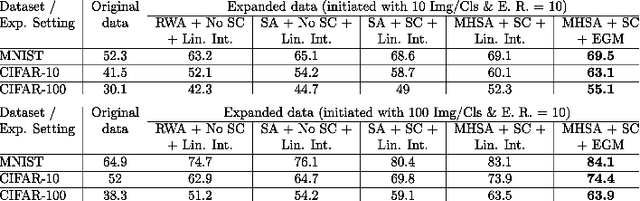
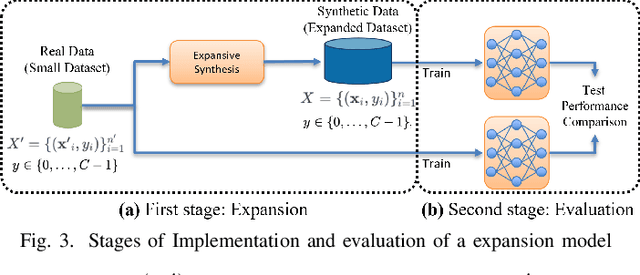
The challenge of limited availability of data for training in machine learning arises in many applications and the impact on performance and generalization is serious. Traditional data augmentation methods aim to enhance training with a moderately sufficient data set. Generative models like Generative Adversarial Networks (GANs) often face problematic convergence when generating significant and diverse data samples. Diffusion models, though effective, still struggle with high computational cost and long training times. This paper introduces an innovative Expansive Synthesis model that generates large-scale, high-fidelity datasets from minimal samples. The proposed approach exploits expander graph mappings and feature interpolation to synthesize expanded datasets while preserving the intrinsic data distribution and feature structural relationships. The rationale of the model is rooted in the non-linear property of neural networks' latent space and in its capture by a Koopman operator to yield a linear space of features to facilitate the construction of larger and enriched consistent datasets starting with a much smaller dataset. This process is optimized by an autoencoder architecture enhanced with self-attention layers and further refined for distributional consistency by optimal transport. We validate our Expansive Synthesis by training classifiers on the generated datasets and comparing their performance to classifiers trained on larger, original datasets. Experimental results demonstrate that classifiers trained on synthesized data achieve performance metrics on par with those trained on full-scale datasets, showcasing the model's potential to effectively augment training data. This work represents a significant advancement in data generation, offering a robust solution to data scarcity and paving the way for enhanced data availability in machine learning applications.