 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVQAScore: Efficient Video Question Answering Data Evaluation
Paper and Code
Nov 11, 2024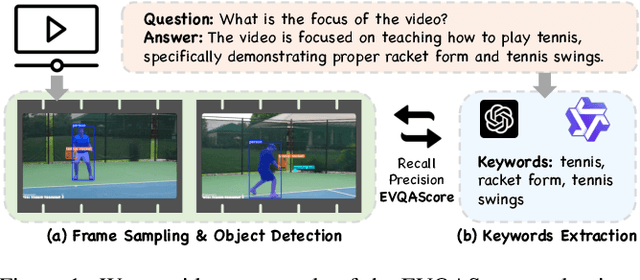



Video question-answering (QA) is a core task in video understanding. Evaluating the quality of video QA and video caption data quality for training video large language models (VideoLLMs) is an essential challenge. Although various methods have been proposed for assessing video caption quality, there remains a lack of dedicated evaluation methods for Video QA. To address this gap, we introduce EVQAScore, a reference-free method that leverages keyword extraction to assess both video caption and video QA data quality. Additionally, we incorporate frame sampling and rescaling techniques to enhance the efficiency and robustness of our evaluation, this enables our score to evaluate the quality of extremely long videos. Our approach achieves state-of-the-art (SOTA) performance (32.8 for Kendall correlation and 42.3 for Spearman correlation, 4.7 and 5.9 higher than the previous method PAC-S++) on the VATEX-EVAL benchmark for video caption evaluation. Furthermore, by using EVQAScore for data selection, we achieved SOTA results with only 12.5\% of the original data volume, outperforming the previous SOTA method PAC-S and 100\% of data.