 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEViT: Privacy-Preserving Image Retrieval via Encrypted Vision Transformer in Cloud Computing
Paper and Code
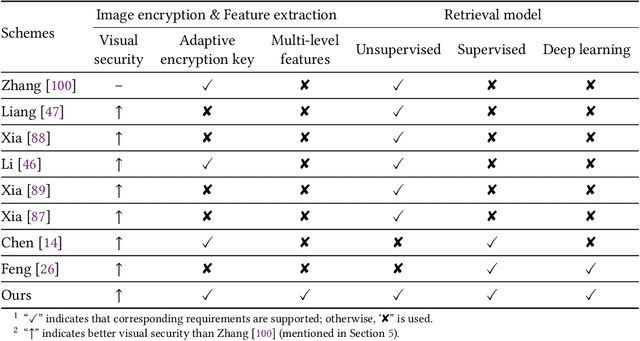
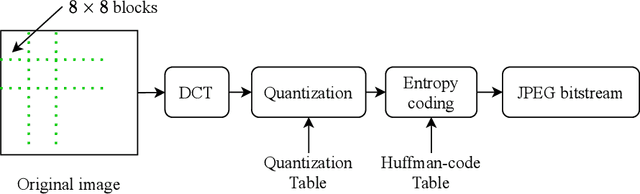
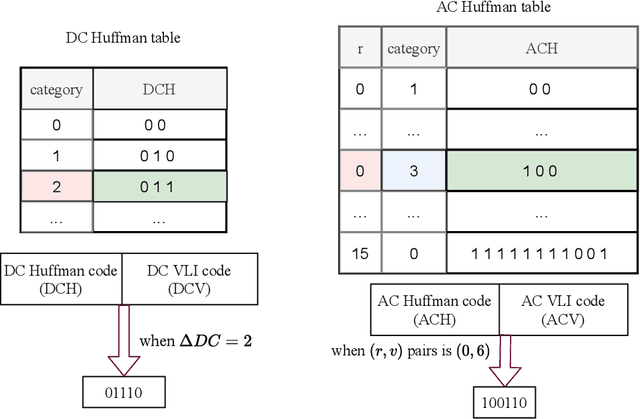
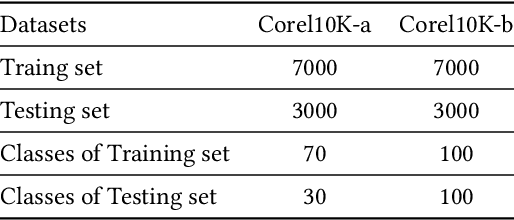
Image retrieval systems help users to browse and search among extensive images in real-time. With the rise of cloud computing, retrieval tasks are usually outsourced to cloud servers. However, the cloud scenario brings a daunting challenge of privacy protection as cloud servers cannot be fully trusted. To this end, image-encryption-based privacy-preserving image retrieval schemes have been developed, which first extract features from cipher-images, and then build retrieval models based on these features. Yet, most existing approaches extract shallow features and design trivial retrieval models, resulting in insufficient expressiveness for the cipher-images. In this paper, we propose a novel paradigm named Encrypted Vision Transformer (EViT), which advances the discriminative representations capability of cipher-images. First, in order to capture comprehensive ruled information, we extract multi-level local length sequence and global Huffman-code frequency features from the cipher-images which are encrypted by stream cipher during JPEG compression process. Second, we design the Vision Transformer-based retrieval model to couple with the multi-level features, and propose two adaptive data augmentation methods to improve representation power of the retrieval model. Our proposal can be easily adapted to unsupervised and supervised settings via self-supervised contrastive learning manner. Extensive experiments reveal that EViT achieves both excellent encryption and retrieval performance, outperforming current schemes in terms of retrieval accuracy by large margins while protecting image privacy effectively. Code is publicly available at \url{https://github.com/onlinehuazai/EViT}.