 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverybody Needs a Little HELP: Explaining Graphs via Hierarchical Concepts
Paper and Code
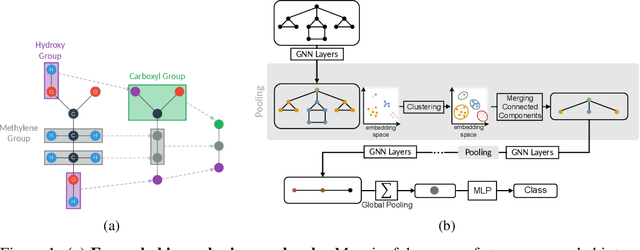

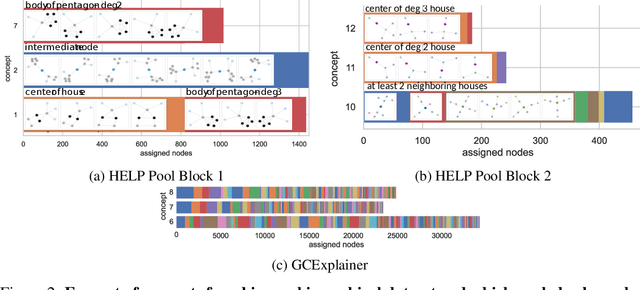

Graph neural networks (GNNs) have led to major breakthroughs in a variety of domains such as drug discovery, social network analysis, and travel time estimation. However, they lack interpretability which hinders human trust and thereby deployment to settings with high-stakes decisions. A line of interpretable methods approach this by discovering a small set of relevant concepts as subgraphs in the last GNN layer that together explain the prediction. This can yield oversimplified explanations, failing to explain the interaction between GNN layers. To address this oversight, we provide HELP (Hierarchical Explainable Latent Pooling), a novel, inherently interpretable graph pooling approach that reveals how concepts from different GNN layers compose to new ones in later steps. HELP is more than 1-WL expressive and is the first non-spectral, end-to-end-learnable, hierarchical graph pooling method that can learn to pool a variable number of arbitrary connected components. We empirically demonstrate that it performs on-par with standard GCNs and popular pooling methods in terms of accuracy while yielding explanations that are aligned with expert knowledge in the domains of chemistry and social networks. In addition to a qualitative analysis, we employ concept completeness scores as well as concept conformity, a novel metric to measure the noise in discovered concepts, quantitatively verifying that the discovered concepts are significantly easier to fully understand than those from previous work. Our work represents a first step towards an understanding of graph neural networks that goes beyond a set of concepts from the final layer and instead explains the complex interplay of concepts on different levels.