 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of the impact of the indiscernibility relation on the fuzzy-rough nearest neighbours algorithm
Paper and Code


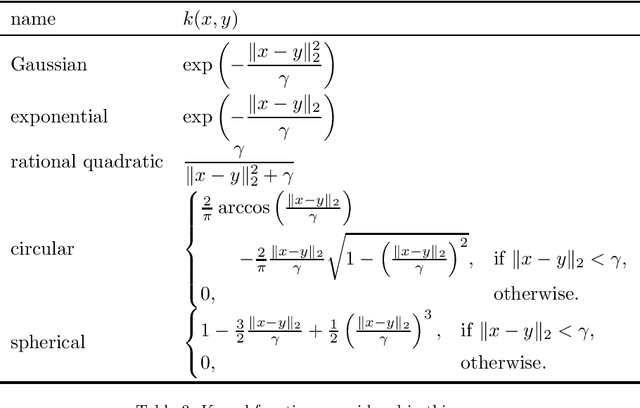

Fuzzy rough sets are well-suited for working with vague, imprecise or uncertain information and have been succesfully applied in real-world classification problems. One of the prominent representatives of this theory is fuzzy-rough nearest neighbours (FRNN), a classification algorithm based on the classical k-nearest neighbours algorithm. The crux of FRNN is the indiscernibility relation, which measures how similar two elements in the data set of interest are. In this paper, we investigate the impact of this indiscernibility relation on the performance of FRNN classification. In addition to relations based on distance functions and kernels, we also explore the effect of distance metric learning on FRNN for the first time. Furthermore, we also introduce an asymmetric, class-specific relation based on the Mahalanobis distance which uses the correlation within each class, and which shows a significant improvement over the regular Mahalanobis distance, but is still beaten by the Manhattan distance. Overall, the Neighbourhood Components Analysis algorithm is found to be the best performer, trading speed for accuracy.