 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Framework For Large-scale Federated Learning
Paper and Code
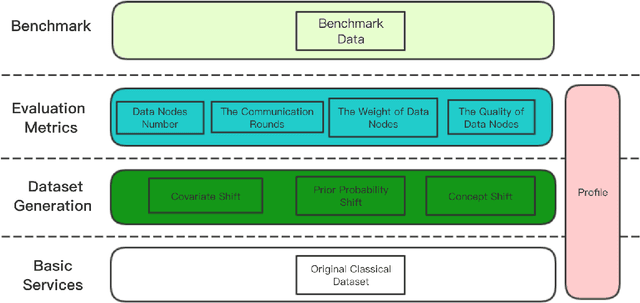



Federated learning is proposed as a machine learning setting to enable distributed edge devices, such as mobile phones, to collaboratively learn a shared prediction model while keeping all the training data on device, which can not only take full advantage of data distributed across millions of nodes to train a good model but also protect data privacy. However, learning in scenario above poses new challenges. In fact, data across a massive number of unreliable devices is likely to be non-IID (identically and independently distributed), which may make the performance of models trained by federated learning unstable. In this paper, we introduce a framework designed for large-scale federated learning which consists of approaches to generating dataset and modular evaluation framework. Firstly, we construct a suite of open-source non-IID datasets by providing three respects including covariate shift, prior probability shift, and concept shift, which are grounded in real-world assumptions. In addition, we design several rigorous evaluation metrics including the number of network nodes, the size of datasets, the number of communication rounds and communication resources etc. Finally, we present an open-source benchmark for large-scale federated learning research.