 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Benchmarks and Learning Criteriafor Discourse-Aware Sentence Representations
Paper and Code
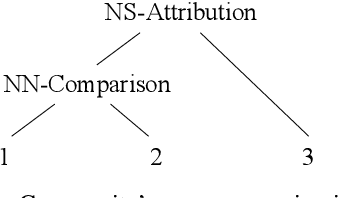



Prior work on pretrained sentence embeddings and benchmarks focus on the capabilities of stand-alone sentences. We propose DiscoEval, a test suite of tasks to evaluate whether sentence representations include broader context information. We also propose a variety of training objectives that makes use of natural annotations from Wikipedia to build sentence encoders capable of modeling discourse. We benchmark sentence encoders pretrained with our proposed training objectives, as well as other popular pretrained sentence encoders on DiscoEval and other sentence evaluation tasks. Empirically, we show that these training objectives help to encode different aspects of information in document structures. Moreover, BERT and ELMo demonstrate strong performances over DiscoEval with individual hidden layers showing different characteristics.