 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Translation Performance of Large Language Models Based on Euas-20
Paper and Code
Aug 06, 2024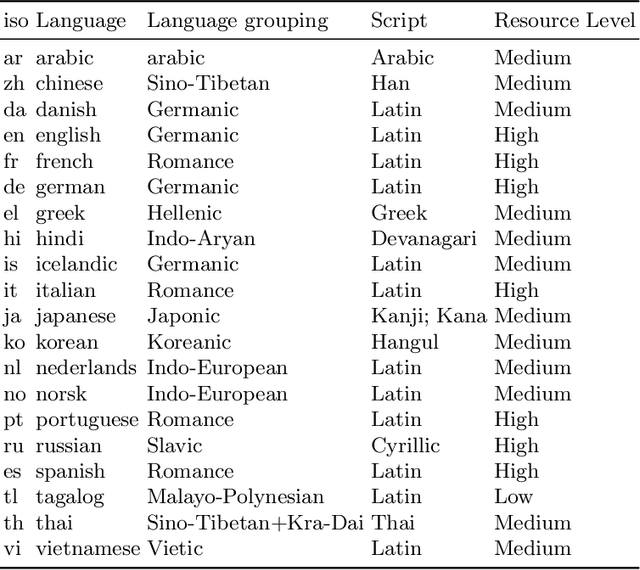


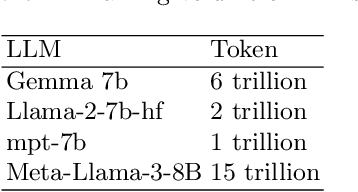
In recent years, with the rapid development of deep learning technology, large language models (LLMs) such as BERT and GPT have achieved breakthrough results in natural language processing tasks. Machine translation (MT), as one of the core tasks of natural language processing, has also benefited from the development of large language models and achieved a qualitative leap. Despite the significant progress in translation performance achieved by large language models, machine translation still faces many challenges. Therefore, in this paper, we construct the dataset Euas-20 to evaluate the performance of large language models on translation tasks, the translation ability on different languages, and the effect of pre-training data on the translation ability of LLMs for researchers and developers.