 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating robustness of language models for chief complaint extraction from patient-generated text
Paper and Code
Nov 15, 2019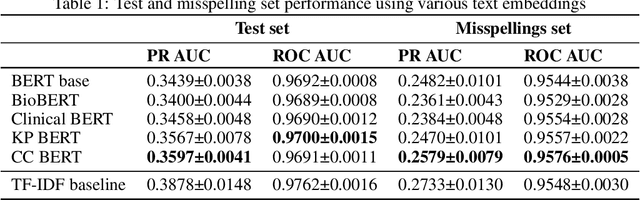
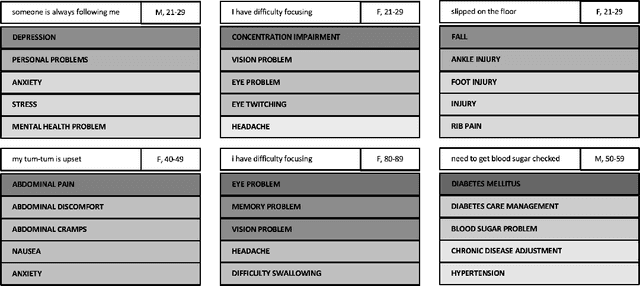
Automated classification of chief complaints from patient-generated text is a critical first step in developing scalable platforms to triage patients without human intervention. In this work, we evaluate several approaches to chief complaint classification using a novel Chief Complaint (CC) Dataset that contains ~200,000 patient-generated reasons-for-visit entries mapped to a set of 795 discrete chief complaints. We examine the use of several fine-tuned bidirectional transformer (BERT) models trained on both unrelated texts as well as on the CC dataset. We contrast this performance with a TF-IDF baseline. Our evaluation has three components: (1) a random test hold-out from the original dataset; (2) a "misspelling set," consisting of a hand-selected subset of the test set, where every entry has at least one misspelling; (3) a separate experimenter-generated free-text set. We find that the TF-IDF model performs significantly better than the strongest BERT-based model on the test (best BERT PR-AUC $0.3597 \pm 0.0041$ vs TF-IDF PR-AUC $0.3878 \pm 0.0148$, $p=7\cdot 10^{-5}$), and is statistically comparable to the misspelling sets (best BERT PR-AUC $0.2579 \pm 0.0079$ vs TF-IDF PR-AUC $0.2733 \pm 0.0130$, $p=0.06$). However, when examining model predictions on experimenter-generated queries, some concerns arise about TF-IDF baseline's robustness. Our results suggest that in certain tasks, simple language embedding baselines may be very performant; however, truly understanding their robustness requires further analysis.