 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Prediction-Time Batch Normalization for Robustness under Covariate Shift
Paper and Code
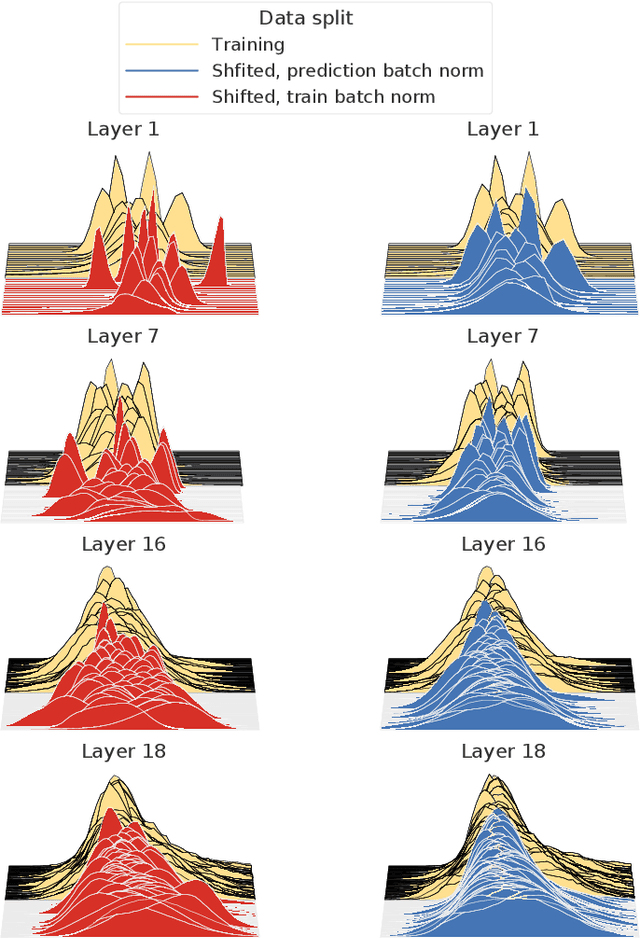
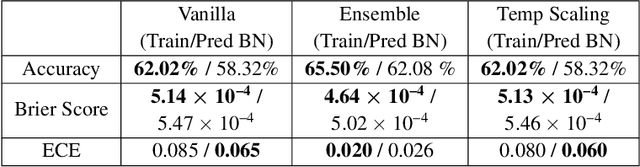
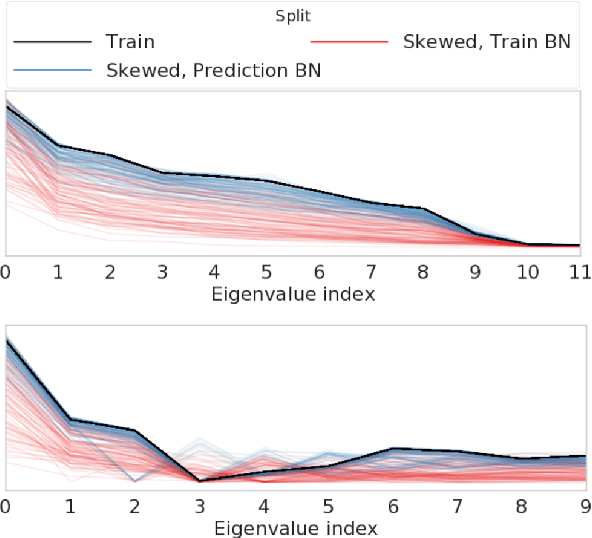
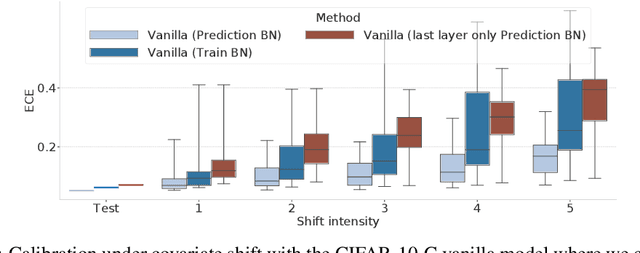
Covariate shift has been shown to sharply degrade both predictive accuracy and the calibration of uncertainty estimates for deep learning models. This is worrying, because covariate shift is prevalent in a wide range of real world deployment settings. However, in this paper, we note that frequently there exists the potential to access small unlabeled batches of the shifted data just before prediction time. This interesting observation enables a simple but surprisingly effective method which we call prediction-time batch normalization, which significantly improves model accuracy and calibration under covariate shift. Using this one line code change, we achieve state-of-the-art on recent covariate shift benchmarks and an mCE of 60.28\% on the challenging ImageNet-C dataset; to our knowledge, this is the best result for any model that does not incorporate additional data augmentation or modification of the training pipeline. We show that prediction-time batch normalization provides complementary benefits to existing state-of-the-art approaches for improving robustness (e.g. deep ensembles) and combining the two further improves performance. Our findings are supported by detailed measurements of the effect of this strategy on model behavior across rigorous ablations on various dataset modalities. However, the method has mixed results when used alongside pre-training, and does not seem to perform as well under more natural types of dataset shift, and is therefore worthy of additional study. We include links to the data in our figures to improve reproducibility, including a Python notebooks that can be run to easily modify our analysis at https://colab.research.google.com/drive/11N0wDZnMQQuLrRwRoumDCrhSaIhkqjof.