Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating the Fundamental Limits is Easier than Achieving the Fundamental Limits
Paper and Code
Oct 01, 2017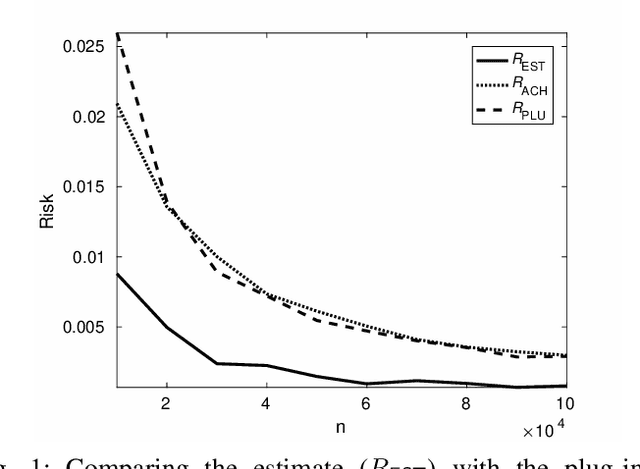
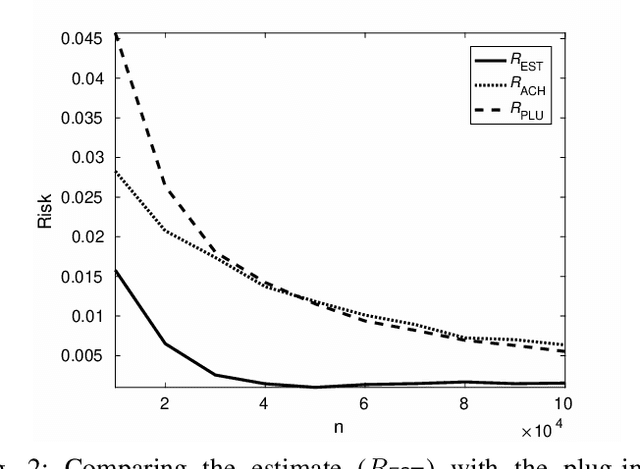
We show through case studies that it is easier to estimate the fundamental limits of data processing than to construct explicit algorithms to achieve those limits. Focusing on binary classification, data compression, and prediction under logarithmic loss, we show that in the finite space setting, when it is possible to construct an estimator of the limits with vanishing error with $n$ samples, it may require at least $n\ln n$ samples to construct an explicit algorithm to achieve the limits.
View paper on