 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErrors-in-variables models with dependent measurements
Paper and Code
Apr 01, 2017
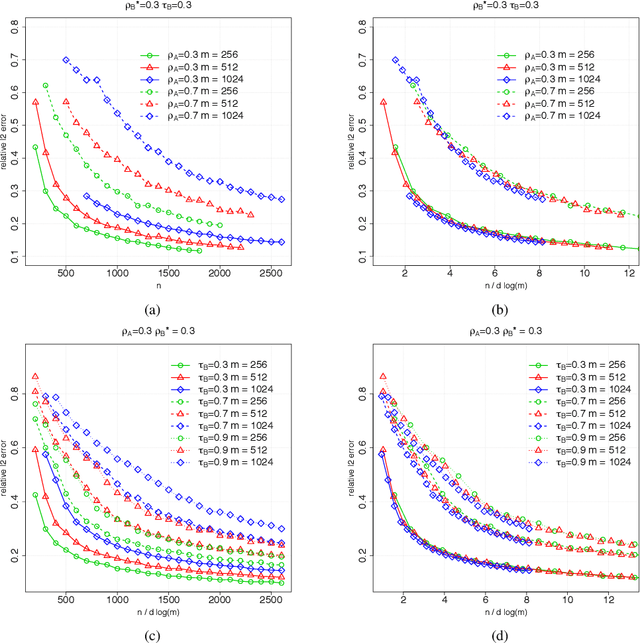
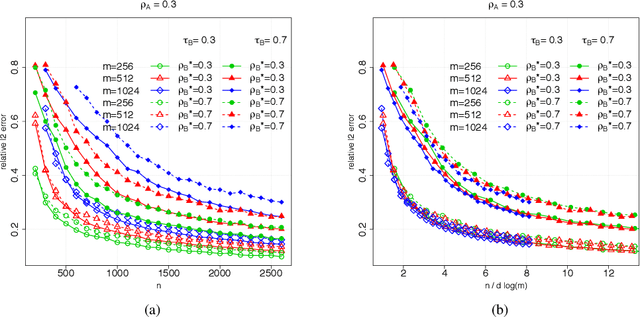
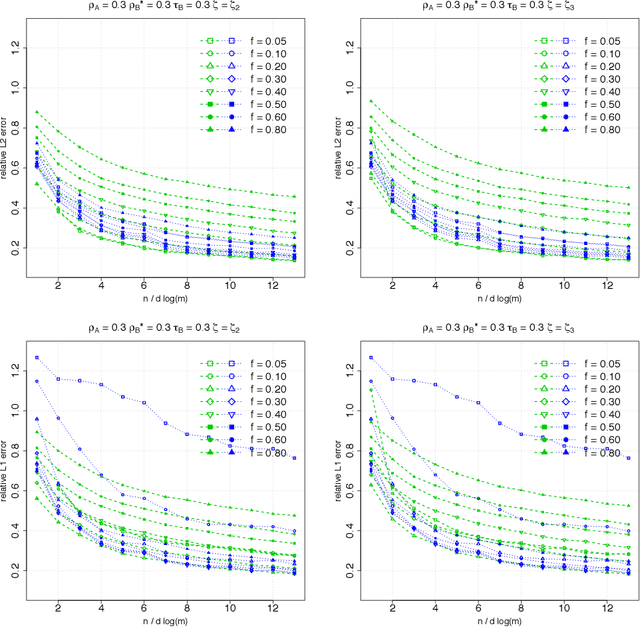
Suppose that we observe $y \in \mathbb{R}^n$ and $X \in \mathbb{R}^{n \times m}$ in the following errors-in-variables model: \begin{eqnarray*} y & = & X_0 \beta^* +\epsilon \\ X & = & X_0 + W, \end{eqnarray*} where $X_0$ is an $n \times m$ design matrix with independent subgaussian row vectors, $\epsilon \in \mathbb{R}^n$ is a noise vector and $W$ is a mean zero $n \times m$ random noise matrix with independent subgaussian column vectors, independent of $X_0$ and $\epsilon$. This model is significantly different from those analyzed in the literature in the sense that we allow the measurement error for each covariate to be a dependent vector across its $n$ observations. Such error structures appear in the science literature when modeling the trial-to-trial fluctuations in response strength shared across a set of neurons. Under sparsity and restrictive eigenvalue type of conditions, we show that one is able to recover a sparse vector $\beta^* \in \mathbb{R}^m$ from the model given a single observation matrix $X$ and the response vector $y$. We establish consistency in estimating $\beta^*$ and obtain the rates of convergence in the $\ell_q$ norm, where $q = 1, 2$. We show error bounds which approach that of the regular Lasso and the Dantzig selector in case the errors in $W$ are tending to 0. We analyze the convergence rates of the gradient descent methods for solving the nonconvex programs and show that the composite gradient descent algorithm is guaranteed to converge at a geometric rate to a neighborhood of the global minimizers: the size of the neighborhood is bounded by the statistical error in the $\ell_2$ norm. Our analysis reveals interesting connections between computational and statistical efficiency and the concentration of measure phenomenon in random matrix theory. We provide simulation evidence illuminating the theoretical predictions.