 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Transformer is all you need
Paper and Code
Oct 20, 2023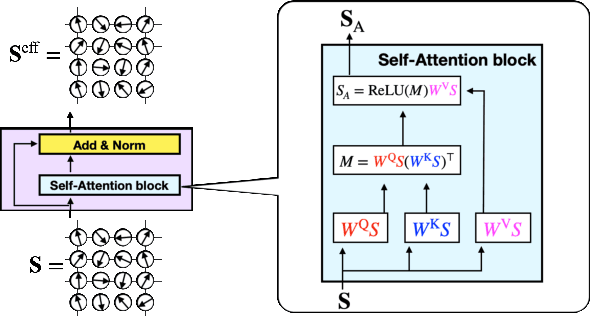
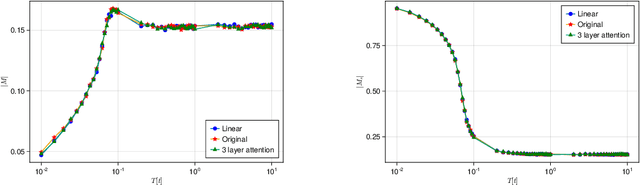
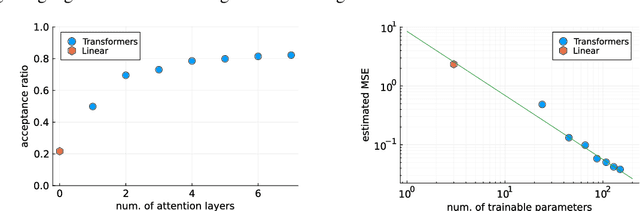
Machine learning, deep learning, has been accelerating computational physics, which has been used to simulate systems on a lattice. Equivariance is essential to simulate a physical system because it imposes a strong induction bias for the probability distribution described by a machine learning model. This reduces the risk of erroneous extrapolation that deviates from data symmetries and physical laws. However, imposing symmetry on the model sometimes occur a poor acceptance rate in self-learning Monte-Carlo (SLMC). On the other hand, Attention used in Transformers like GPT realizes a large model capacity. We introduce symmetry equivariant attention to SLMC. To evaluate our architecture, we apply it to our proposed new architecture on a spin-fermion model on a two-dimensional lattice. We find that it overcomes poor acceptance rates for linear models and observe the scaling law of the acceptance rate as in the large language models with Transformers.