 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivalence of Convergence Rates of Posterior Distributions and Bayes Estimators for Functions and Nonparametric Functionals
Paper and Code
Nov 27, 2020
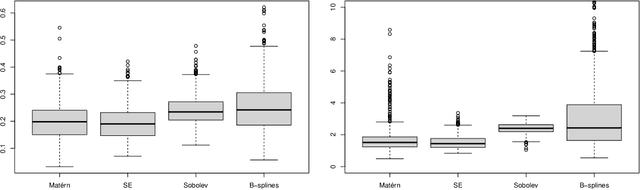
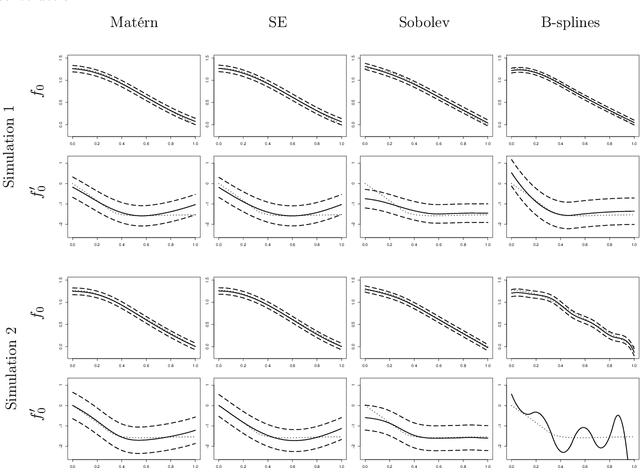
We study the posterior contraction rates of a Bayesian method with Gaussian process priors in nonparametric regression and its plug-in property for differential operators. For a general class of kernels, we establish convergence rates of the posterior measure of the regression function and its derivatives, which are both minimax optimal up to a logarithmic factor for functions in certain classes. Our calculation shows that the rate-optimal estimation of the regression function and its derivatives share the same choice of hyperparameter, indicating that the Bayes procedure remarkably adapts to the order of derivatives and enjoys a generalized plug-in property that extends real-valued functionals to function-valued functionals. This leads to a practically simple method for estimating the regression function and its derivatives, whose finite sample performance is assessed using simulations. Our proof shows that, under certain conditions, to any convergence rate of Bayes estimators there corresponds the same convergence rate of the posterior distributions (i.e., posterior contraction rate), and vice versa. This equivalence holds for a general class of Gaussian processes and covers the regression function and its derivative functionals, under both the $L_2$ and $L_{\infty}$ norms. In addition to connecting these two fundamental large sample properties in Bayesian and non-Bayesian regimes, such equivalence enables a new routine to establish posterior contraction rates by calculating convergence rates of nonparametric point estimators. At the core of our argument is an operator-theoretic framework for kernel ridge regression and equivalent kernel techniques. We derive a range of sharp non-asymptotic bounds that are pivotal in establishing convergence rates of nonparametric point estimators and the equivalence theory, which may be of independent interest.