 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
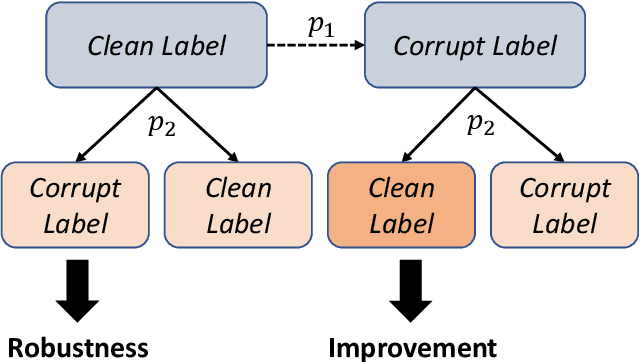
Add to EdgeEpoch-wise label attacks for robustness against label noise
Paper and Code
Dec 12, 2019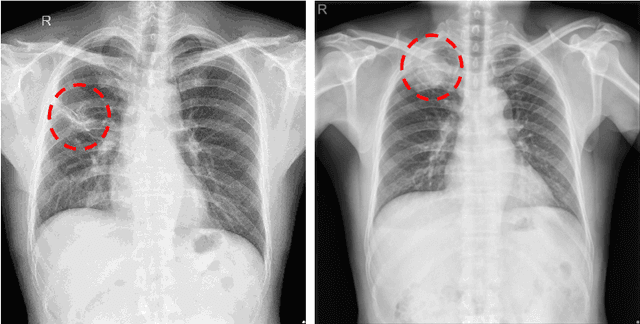


The current accessibility to large medical datasets for training convolutional neural networks is tremendously high. The associated dataset labels are always considered to be the real "ground truth". However, the labeling procedures often seem to be inaccurate and many wrong labels are integrated. This may have fatal consequences on the performance of both training and evaluation. In this paper, we show the impact of label noise in the training set on a specific medical problem based on chest X-ray images. With a simple one-class problem, the classification of tuberculosis, we measure the performance on a clean evaluation set when training with label-corrupt data. We develop a method to compete with incorrectly labeled data during training by randomly attacking labels on individual epochs. The network tends to be robust when flipping correct labels for a single epoch and initiates a good step to the optimal minimum on the error surface when flipping noisy labels. On a baseline with an AUC (Area under Curve) score of 0.924, the performance drops to 0.809 when 30% of our training data is misclassified. With our approach the baseline performance could almost be maintained, the performance raised to 0.918.