 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Risk-Sensitive Reinforcement Learning
Paper and Code
Jun 14, 2019
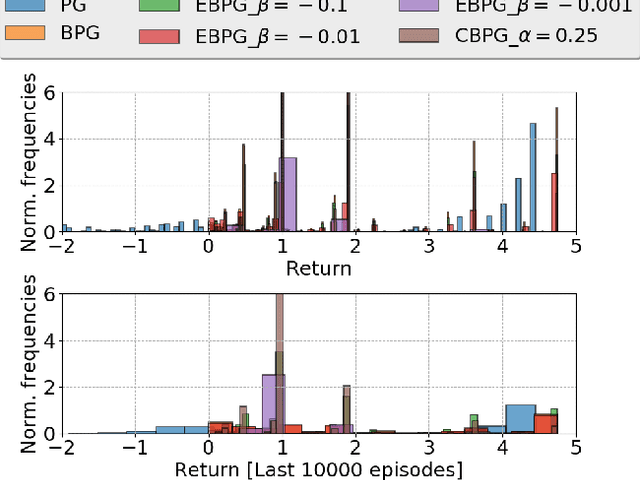
We develop a framework for interacting with uncertain environments in reinforcement learning (RL) by leveraging preferences in the form of utility functions. We claim that there is value in considering different risk measures during learning. In this framework, the preference for risk can be tuned by variation of the parameter $\beta$ and the resulting behavior can be risk-averse, risk-neutral or risk-taking depending on the parameter choice. We evaluate our framework for learning problems with model uncertainty. We measure and control for \emph{epistemic} risk using dynamic programming (DP) and policy gradient-based algorithms. The risk-averse behavior is then compared with the behavior of the optimal risk-neutral policy in environments with epistemic risk.