 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntangled Watermarks as a Defense against Model Extraction
Paper and Code
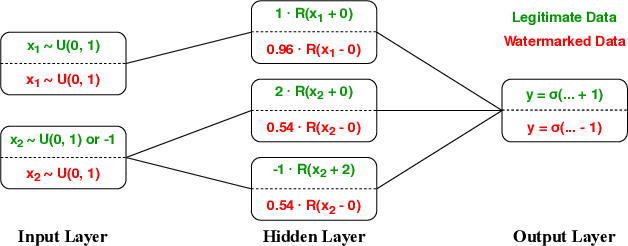


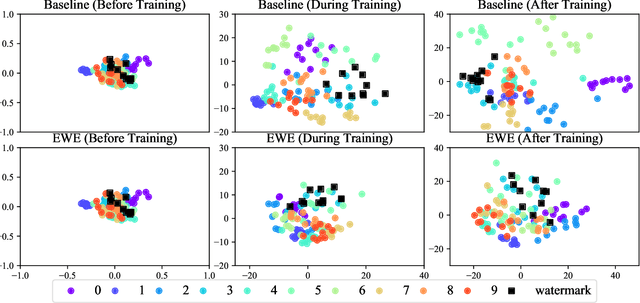
Machine learning involves expensive data collection and training procedures. Model owners may be concerned that valuable intellectual property can be leaked if adversaries mount model extraction attacks. Because it is difficult to defend against model extraction without sacrificing significant prediction accuracy, watermarking leverages unused model capacity to have the model overfit to outlier input-output pairs, which are not sampled from the task distribution and are only known to the defender. The defender then demonstrates knowledge of the input-output pairs to claim ownership of the model at inference. The effectiveness of watermarks remains limited because they are distinct from the task distribution and can thus be easily removed through compression or other forms of knowledge transfer. We introduce Entangled Watermarking Embeddings (EWE). Our approach encourages the model to learn common features for classifying data that is sampled from the task distribution, but also data that encodes watermarks. An adversary attempting to remove watermarks that are entangled with legitimate data is also forced to sacrifice performance on legitimate data. Experiments on MNIST, Fashion-MNIST, and Google Speech Commands validate that the defender can claim model ownership with 95% confidence after less than 10 queries to the stolen copy, at a modest cost of 1% accuracy in the defended model's performance.