 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsembling Textual and Structure-Based Models for Knowledge Graph Completion
Paper and Code
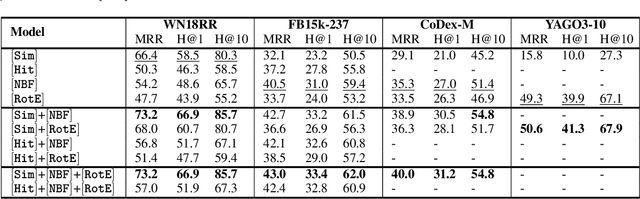
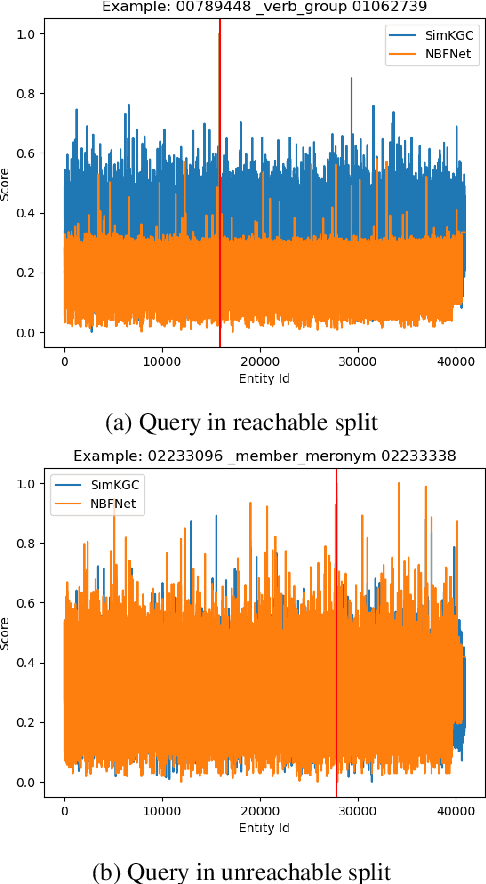
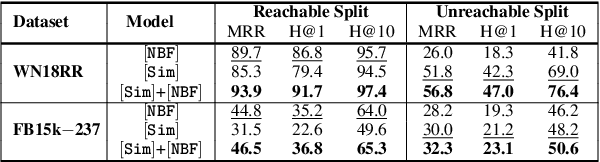
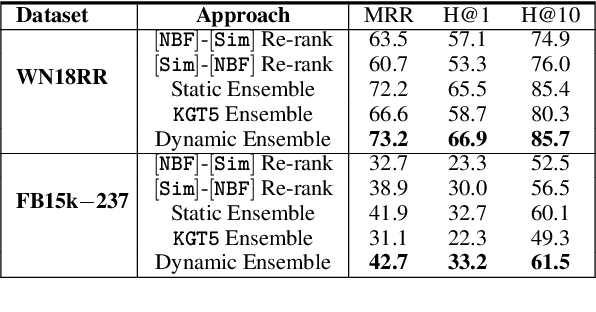
We consider two popular approaches to Knowledge Graph Completion (KGC): textual models that rely on textual entity descriptions, and structure-based models that exploit the connectivity structure of the Knowledge Graph (KG). Preliminary experiments show that these approaches have complementary strengths: structure-based models perform well when the gold answer is easily reachable from the query head in the KG, while textual models exploit descriptions to give good performance even when the gold answer is not reachable. In response, we explore ensembling as a way of combining the best of both approaches. We propose a novel method for learning query-dependent ensemble weights by using the distributions of scores assigned by individual models to all candidate entities. Our ensemble baseline achieves state-of-the-art results on three standard KGC datasets, with up to 6.8 pt MRR and 8.3 pt Hits@1 gains over best individual models.